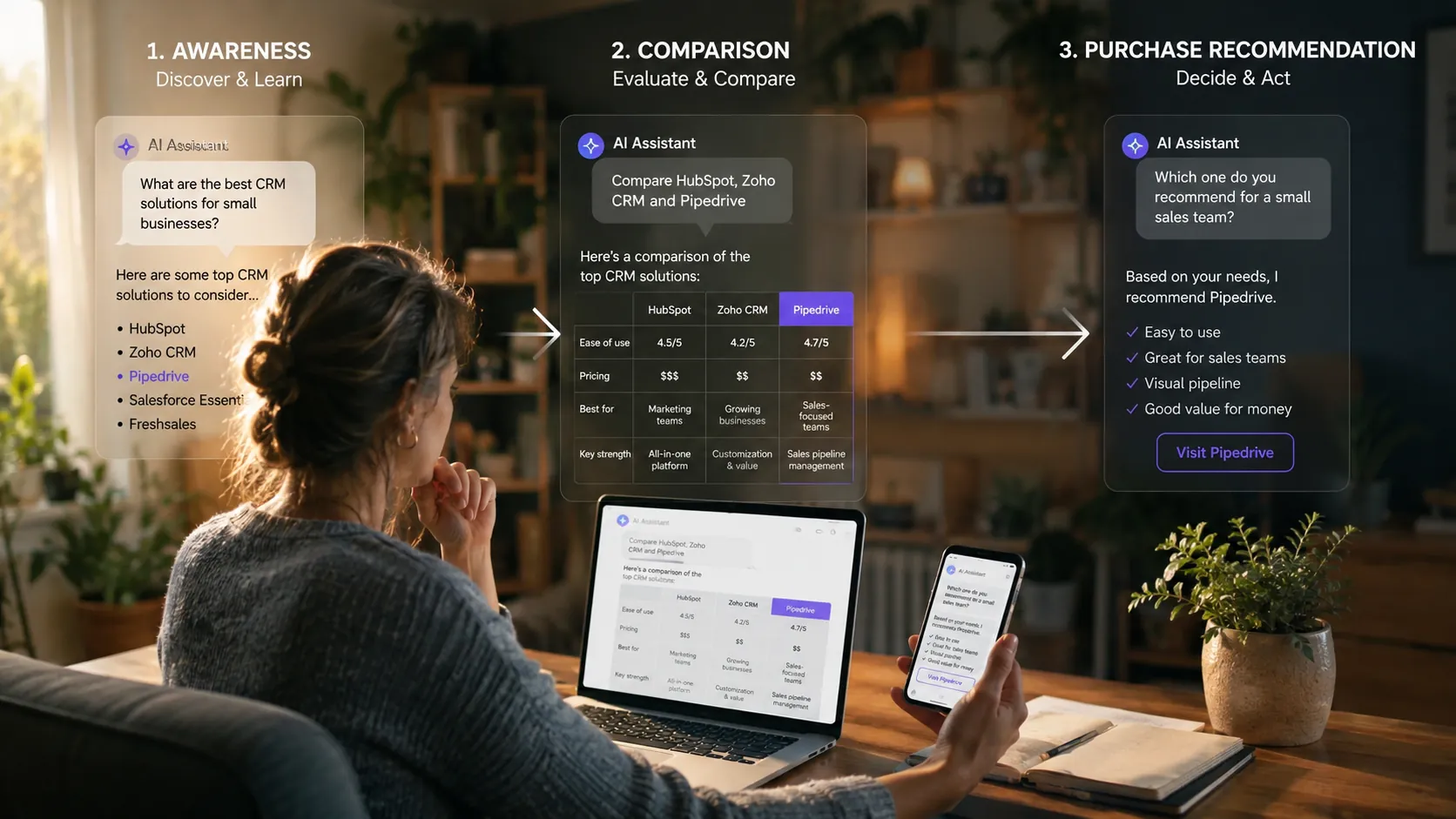
Si vous demandez à un consultant SEO ou à un outil SaaS d'auditer la visibilité de votre marque dans les moteurs génératifs, il vous livrera presque toujours une seule matrice : un tableau questions x LLM où l'on regarde si votre marque est citée. C'est utile, mais c'est insuffisant. Cette matrice unique répond seulement à la question : « Suis-je cité quand un acheteur potentiel me cherche ? ». Elle ne dit rien sur ce qui se passe avant l'intention d'achat, ni sur la manière dont le modèle vous compare aux autres acteurs, ni sur le sentiment qu'il associe à votre nom.
Si vous voulez piloter votre visibilité dans les LLM aussi finement que vous pilotez votre SEO classique, il vous faut trois mesures distinctes, qui correspondent aux trois grandes étapes du parcours d'achat. Et au milieu du parcours, il vous faut même deux sous-mesures complémentaires qu'il ne faut surtout pas confondre. Cet article vous donne la méthode pour identifier les bons prompts à chaque étape, et il s'appuie sur mes propres chiffres mesurés sur ma propre marque, en transparence totale, le 8 mai 2026.
À retenir avant de plonger dans la méthode
- Un prompt unique ne mesure jamais la visibilité d'une marque dans les LLM dans son ensemble. Il mesure une tranche du parcours d'achat.
- Trois étapes, trois familles de prompts : notoriété spontanée en haut du parcours, considération comparée au milieu, citabilité d'achat en bas.
- Au milieu du parcours, deux sous-mesures distinctes : (a) le voisinage forcé et l'alternative, qui se mesure en taux de citation ; (b) le sentiment comparatif, qui se lit dans les verbatims des LLM.
- Compter une réapparition de votre nom dans un prompt qui vous nomme est une mesure triviale. Ce qui est mesurable dans ce cas, c'est le sentiment associé à votre nom comparé à celui des autres acteurs nommés.
- L'article qui suit donne le prompt-type, la métrique et un exemple chiffré pour chaque étape, avec mes propres données du 8 mai 2026.
Essayer mon outil générateur de prompts BoFu.
Pourquoi un seul prompt ne suffit pas pour mesurer une marque dans les LLM
Quand vous mesurez votre visibilité Google, vous ne regardez pas seulement les requêtes de marque. Vous regardez aussi les requêtes informationnelles, les requêtes navigationnelles, les requêtes commerciales, les longues traînes. Chaque famille de requêtes mesure une partie différente de votre présence en ligne.
Avec les moteurs génératifs, il en va de même. Un prompt qui demande « Quel consultant SEO recommandez-vous en France ? » mesure la fin du parcours : un acheteur qui sait déjà ce qu'il cherche et qui veut un nom. Un prompt qui demande « Cite-moi 15 voix françaises sur la visibilité dans les LLM » mesure le haut du parcours : votre notoriété spontanée, sans aucun signal d'intention d'achat. Et un prompt qui demande « Compare X, Y et Z » mesure le milieu : la considération comparée, c'est-à-dire la manière dont le modèle vous positionne par rapport à vos concurrents quand on vous met dans le ring.
Trois étapes, trois prompts différents, trois matrices différentes. Si vous mélangez les trois, vous obtenez un audit qui ne dit rien de précis sur où agir.
Étape 1. La notoriété spontanée : ce que mesurent les prompts du haut du parcours
Définition opérationnelle : la notoriété spontanée mesure si votre marque est citée par le modèle sans aucun signal d'intention d'achat dans la question. C'est l'équivalent du test « citez-moi cinq marques de café » qu'utilisent les études de marque depuis cinquante ans, transposé aux LLM.
Métrique : taux d'évocation libre (vous apparaissez ou non dans la liste demandée) et rang dans la liste si vous y êtes. Le rang compte parce que les modèles citent rarement plus de dix à quinze acteurs, et qu'un acheteur lit rarement au-delà des cinq premiers.
Prompt-type : la formulation est volontairement large et demande une liste longue. Trois exemples qui marchent bien :
- « Cite-moi 15 [type d'acteur] qui [activité ou expertise relative au secteur]. »
- « Quels sont les [acteurs] les plus actifs sur [sujet] en 2026 ? »
- « Cite-moi 10 voix [pays ou langue] qui publient sur [thématique]. »
Règle critique : aucune mention de votre marque, aucun synonyme de votre offre, aucun descriptif géographique trop unique. Vous testez si le modèle vous récupère de mémoire, pas si vous savez l'orienter.
Exemple chiffré sur ma propre marque (8 mai 2026)
J'ai mesuré trois prompts de notoriété spontanée sur cinq LLM (Perplexity Sonar, GPT-5 mini, Claude Haiku 4.5, Gemini 3 Flash, Grok 4.1 Fast). Voici les chiffres bruts :
| Prompt notoriété spontanée | Perplexity | GPT-5 mini | Claude | Gemini | Grok |
|---|---|---|---|---|---|
| 15 consultants SEO français qui parlent IA générative et GEO | ✅ #1 🔗 | ❌ absent | ✅ #2 | ❌ absent | ✅ #1 🔗 |
| Experts francophones les plus actifs sur le GEO en 2026 | ❌ absent | ❌ absent | ❌ absent | ❌ absent | ❌ absent |
| 10 voix françaises sur la visibilité des marques dans les LLM | ❌ absent | ❌ absent | ❌ absent | ❌ absent | ❌ absent |
Score notoriété spontanée : 3 citations sur 15 mesures, soit 20 %. Un seul prompt fonctionne (le premier), les deux autres sont des trous noirs. Voisinage cité par les modèles : Stéphanie Barge, Paul Vengeons, Kévin Papot, Frédéric Poulet, Adrien Beaujeu, Sébastien Vallat. Cette carte de voisinage, à elle seule, donne une feuille de route éditoriale : ce sont les noms à fréquenter dans les sources que les LLM récupèrent.
L'enseignement de fond, c'est que dès que la requête contient le couple « moteurs IA et LLM » au lieu de « SEO et GEO », je disparais. Le shift sémantique GEO vers IA n'est pas encore acté dans ma cartographie LLM. C'est un angle mort que la mesure du haut du parcours permet d'identifier avec une précision qu'aucune autre famille de prompts ne donne.
Étape 2. La considération comparée : ce que mesurent les prompts du milieu du parcours
Définition opérationnelle : la considération comparée mesure votre positionnement quand vous êtes mis dans le ring avec d'autres acteurs nommés. Ce n'est plus la mémoire libre du modèle, c'est sa capacité à vous différencier et à vous situer.
Cette étape se mesure de deux manières complémentaires, et il est important de ne pas les confondre :
- 2a. Le voisinage forcé et l'alternative. Vous citez un concurrent dans le prompt, mais pas votre marque. Vous mesurez si le modèle vous récupère comme alternative ou comme voisin sémantique. La métrique reste un taux de citation, et la mesure n'est pas biaisée parce que rien dans le prompt ne pousse votre nom dans la réponse.
- 2b. Le sentiment comparatif. Vous citez votre marque avec deux ou trois concurrents nommés. La citation devient triviale (le modèle reprend les noms qu'on lui donne). Ce qui est mesurable dans ce cas, c'est le sentiment associé à chaque nom et la nature des descriptifs employés. Cette mesure se lit en lecture qualitative des verbatims, pas en taux de citation.
2a. Voisinage forcé et alternative — chiffres bruts (8 mai 2026)
Deux prompts dans cette catégorie, où ma marque n'apparaît pas dans la question :
| Prompt voisinage et alternative | Perplexity | GPT-5 mini | Claude | Gemini | Grok |
|---|---|---|---|---|---|
| Alternative à Laurent Bourrelly pour une vision plus récente du GEO et des LLM | ❌ absent | ❌ absent | ❌ absent | ❌ absent | ❌ absent |
| Comment se situe Sylvain Peyronnet par rapport aux autres consultants spécialisés GEO et LLM | ✅ #1 🔗 | ❌ absent | ✅ cité 🔗 | ❌ absent | ✅ #1 🔗 |
Score voisinage et alternative : 3 citations sur 10 mesures, soit 30 %. L'angle « alternative à » est un trou noir total : aucun modèle ne me code comme remplacement de Bourrelly. À l'inverse, le voisinage forcé fonctionne bien : quand on parle de Peyronnet, je sors trois fois sur cinq, dont deux fois en première position.
L'enseignement est précis. Je suis codé dans l'écosystème LLM comme acteur autonome, pas comme alternative à un autre. C'est un positionnement à confirmer ou à corriger selon votre stratégie : si vous voulez capter le trafic de « qui d'autre que X », il vous faut publier des contenus qui vous positionnent explicitement en alternative.
2b. Sentiment comparatif — verdict qualitatif (8 mai 2026)
Un prompt dans cette catégorie, où je suis cité explicitement avec mes pairs : « Compare les approches de Julien Gourdon, Laurent Bourrelly, Sylvain Peyronnet et Paul Sanchez en matière de SEO et de visibilité dans les moteurs IA ». Comme la réapparition des noms dans la réponse est triviale, je lis les verbatims pour évaluer le sentiment associé à chacun.
| Modèle | Descriptif employé pour ma marque | Position relative aux trois autres |
|---|---|---|
| Perplexity Sonar | « Rares experts francophones », « positionnement de niche expert GEO » | Différencié de Bourrelly (« historique éthique humain ») |
| GPT-5 mini | « Faire de la marque la réponse », méthode answer-first | Réponse incomplète, mais positionnement net |
| Claude Haiku 4.5 | Réponse incomplète, modèle a manqué d'informations sur Sanchez | Pas de verdict |
| Gemini 3 Flash | « Pionnier du GEO et de la Réponse Unique », « s'est imposé » | Verbatim le plus élogieux des cinq modèles |
| Grok 4.1 Fast | « Leader GEO en France », « top 1 consultants GEO 2025 », « futuriste » | Hiérarchise nettement vs Bourrelly (top 4) et Sanchez (« hacker, agressif ») |
Verdict sentiment : positif différenciant sur quatre modèles sur cinq (Claude n'a pas pu compléter sa comparaison). Les descriptifs employés convergent sur trois mots-clés récurrents : pionnier, niche expert, leader GEO France. Cette convergence verbatim a une valeur stratégique forte. C'est la signature dont les LLM se servent quand ils me situent face à mes pairs, et c'est elle qu'il faut entretenir.
Pour comparaison, voici la cartographie de sentiment des trois autres acteurs nommés dans le prompt, telle qu'elle ressort des cinq verbatims agrégés :
- Laurent Bourrelly : « historique, éthique, humain, sémantique classique, pionnier du cocon ». Très positif, ancrage historique.
- Sylvain Peyronnet : « technique, formateur, data, machine learning, moins hype ». Positif mais nuancé sur la centralité du sujet GEO.
- Paul Sanchez : « hacker, agressif, automation, black ou grey hat ». Ambivalent, positionnement de niche technique perçu comme controversé.
Cette cartographie est une matière exploitable directement, beaucoup plus que la simple présence dans la réponse. Elle permet de détecter en quelques minutes si votre signature éditoriale est bien décodée par les LLM, et si elle vous différencie de vos pairs sur les bons attributs.
Étape 3. La citabilité d'achat : ce que mesurent les prompts du bas du parcours
La citabilité d'achat mesure si votre marque est citée par le modèle quand un acheteur potentiel pose une question proche de la décision d'achat, sans jamais nommer votre marque dans la question. C'est l'étape la mieux documentée à ce jour, et j'ai consacré un article complet à la méthode reproductible permettant de la mesurer.
Je n'en redonne pas le détail ici. Je rappelle simplement les chiffres comparables : sur 30 mesures effectuées le 7 mai 2026 selon la méthode CitaScan, je suis cité 9 fois, soit 30 % de citabilité d'achat. Vous trouverez le prompt complet pour générer les questions, la matrice d'audit et le cas pratique chiffré dans l'article dédié.
La matrice 3 x 3 à imprimer et garder en tête
Voici le tableau qui résume tout ce qui précède. Si vous deviez ne retenir qu'un visuel de cet article, c'est celui-ci :
| Étape | Question business | Prompt-type | Métrique principale |
|---|---|---|---|
| Notoriété spontanée (haut du parcours) | Suis-je sur le radar du modèle sans qu'on l'aide ? | « Cite-moi 15 [acteurs] qui [activité] » | Taux d'évocation libre et rang dans la liste |
| Voisinage forcé et alternative (milieu, sans nommer la marque) | Suis-je récupéré comme alternative ou voisin d'un concurrent ? | « Alternative à X » ou « Comment se situe Y » | Taux de citation et rang |
| Sentiment comparatif (milieu, en nommant la marque) | Avec quels mots le modèle me décrit-il face à mes pairs ? | « Compare [Vous], X, Y, Z sur [sujet] » | Lecture qualitative des verbatims, descriptifs récurrents |
| Citabilité d'achat (bas du parcours) | Suis-je cité comme recommandation quand un acheteur veut acheter ? | 30 questions sans mention de marque (méthode CitaScan) | Taux de citation, rang, statut de source |
Cinq erreurs typiques d'attribution funnel dans les audits GEO actuels
En auditant la communication LinkedIn des acteurs SEO et GEO francophones depuis six mois, je relève cinq erreurs récurrentes. Elles ne sont pas anecdotiques, elles biaisent les recommandations de fond.
- Compter une mention triviale comme une citation. Si vous nommez la marque dans le prompt et que vous comptez sa réapparition dans la réponse, vous mesurez la docilité du modèle, pas votre considération réelle. Pour ce type de prompt comparatif, la mesure utile est qualitative : descriptifs employés, sentiment associé, hiérarchie implicite.
- Présenter un score global sans étape. « Citée 12 fois sur 30 dans ChatGPT » ne dit rien tant qu'on ne sait pas si ces 12 citations sont concentrées sur les requêtes informationnelles, comparatives ou commerciales. Le score global lisse l'information utile.
- Mélanger haut et milieu du parcours dans une même matrice. Si vous testez à la fois « Cite 15 acteurs » et « Compare Gourdon vs Bourrelly » dans le même tableau, vous mélangez deux mesures qui n'ont pas la même signification. Toujours séparer.
- Ignorer le sentiment associé en milieu de parcours. Être cité avec un sentiment réservé n'a pas la même valeur qu'une mention élogieuse. La présence ne suffit pas, surtout au milieu du parcours où l'acheteur arbitre.
- Ne mesurer qu'un seul LLM. Les écarts inter-modèles sont énormes. Mes propres données du 8 mai 2026 montrent des taux très différents selon les moteurs. Un audit qui ne couvre qu'un seul moteur est aveugle à plus de la moitié du marché.
Trois enseignements stratégiques que la méthode 3 x 3 fait remonter
Mon audit complet du 8 mai 2026 produit trois enseignements que je n'aurais jamais vus avec un score global. Chacun pointe une action concrète.
- La présence est faible en haut du parcours mais correcte en bas et au milieu (20 % en notoriété spontanée, 30 % en voisinage et alternative, 30 % en citabilité d'achat). Le shift sémantique GEO vers IA n'est pas encore acté dans ma cartographie LLM, ce qui est un angle mort à travailler par des contenus et des mentions externes alignés sur le vocabulaire émergent.
- Le sentiment des LLM est meilleur que ma simple citation. Quand je suis mis dans le ring, quatre modèles sur cinq emploient des descriptifs nettement positifs et différenciants (« pionnier », « niche expert », « leader GEO France »). Ce capital sentiment est une signature stratégique. La citation s'achète par la présence, le sentiment se construit par la qualité éditoriale.
- L'angle alternative est désert. Sur le prompt « alternative à Bourrelly », zéro citation sur cinq modèles. Cela signifie que je ne suis pas codé comme option de remplacement d'un autre. C'est une opportunité précise et chiffrable, qui s'active par des contenus de comparaison directe avec un acteur de référence.
La mesure 3 x 3 ne sert à rien sans cette lecture stratégique. Sans la décomposition par étape et sans la distinction sentiment / citation, je n'aurais vu qu'un score global et je serais passé à côté des leviers à activer en priorité.
Comment commencer dès cette semaine
Voici la séquence que je recommande, dans l'ordre :
- Identifier 3 prompts pour la notoriété spontanée, 3 prompts pour la considération comparée et 30 prompts pour la citabilité d'achat, calibrés sur votre marque et votre catégorie. Pour les prompts du bas du parcours, utilisez le prompt CitaScan publié sur cet article. Pour les autres, suivez les prompts-types donnés ci-dessus, en distinguant bien les prompts qui nomment votre marque (à analyser en sentiment) et ceux qui ne la nomment pas (à analyser en citation).
- Mesurer sur cinq LLM minimum : Perplexity, ChatGPT (via GPT-5 mini), Claude, Gemini, Grok. L'API Agent de Perplexity permet d'accéder à ces cinq modèles avec une seule clé, pour un coût d'environ 0,40 euros pour les six prompts du haut et du milieu, et 1,20 à 2 euros pour les 30 prompts du bas.
- Calculer trois scores séparés et lire les enseignements étape par étape. Aucun score global, surtout au début. Pour les prompts comparatifs où votre marque apparaît, lisez les verbatims plutôt que de compter les citations.
- Recommencer la mesure chaque semaine pendant six semaines, puis espacer. Les deltas par étape sont beaucoup plus parlants que les deltas globaux.
Vous préférez déléguer l'audit complet ?
Si vous voulez un audit 3 x 3 livré en moins d'une semaine, avec interprétation par étape, plan d'action priorisé et suivi hebdomadaire, parlons-en directement.
Demander un audit completQuestions fréquentes sur la mesure 3 x 3
Pourquoi six prompts pour le haut et le milieu du parcours, et 30 pour le bas ?
Parce que le bas du parcours est l'étape de la décision d'achat, donc celle qui produit le plus de variantes commerciales utiles à mesurer. Trois prompts en notoriété spontanée et trois en considération comparée suffisent pour cartographier les angles morts et le voisinage sémantique. Au-delà, vous duplez l'information sans gagner en précision.
Faut-il citer mon nom dans les prompts du haut du parcours ?
Non. La règle est stricte : pas de mention, pas de variante évidente, pas d'expression qui rendrait votre marque devinable pour un humain familier du secteur. Sinon vous biaisez la mesure et vous mesurez votre capacité à orienter le modèle, pas sa mémoire libre.
Faut-il citer mon nom dans les prompts du milieu du parcours ?
Cela dépend de la sous-mesure que vous voulez obtenir. Pour mesurer le voisinage forcé ou l'alternative, ne nommez pas votre marque. La métrique reste un taux de citation, et la mesure n'est pas biaisée. Pour mesurer le sentiment comparatif, nommez votre marque avec deux ou trois concurrents. Mais comptez alors le sentiment dans les verbatims, pas la citation.
Quels sont les bons concurrents à nommer en milieu de parcours ?
Les concurrents directs sur votre coeur de cible, plus un acteur historique reconnu de votre secteur (le « concurrent boussole » qui fait référence dans les sources). Évitez de citer uniquement des acteurs du même profil que vous : vous obtenez alors une matrice qui ne dit rien sur votre cartographie réelle dans le marché.
Comment mesurer concrètement le sentiment associé à un nom dans une réponse de LLM ?
Lisez les verbatims des cinq modèles. Pour chaque modèle, notez les trois ou quatre adjectifs ou descriptifs employés à votre sujet. Comparez ces descriptifs à ceux employés pour vos concurrents nommés dans le même prompt. Repérez les convergences entre modèles : si le même descriptif revient sur trois ou quatre modèles, c'est votre signature. Repérez les divergences : si un modèle vous décrit avec un attribut que les autres n'emploient pas, c'est un signal sur sa source spécifique.
À quelle fréquence refaire la mesure 3 x 3 ?
Au début, une fois par semaine pendant six semaines, après les optimisations majeures. Ensuite, une fois toutes les deux semaines pendant deux mois, puis une fois par mois en croisière. Sur les trois étapes en parallèle, sinon vous perdez la lecture comparative qui fait la valeur de la méthode.
Cette méthode fonctionne-t-elle pour une marque B2C ?
Oui, sans modification de structure. Seuls les prompts changent : le haut du parcours B2C ressemble à « Cite-moi 10 marques de [catégorie produit] », le milieu à « Compare [Marque A] et [Marque B] », et le bas à des questions d'achat précises. La méthode 3 x 3 est agnostique au secteur.
L'audit qui sert vraiment à piloter
Mesurer la visibilité d'une marque dans les LLM avec un seul prompt, c'est l'équivalent d'évaluer son SEO en regardant uniquement le trafic de la page d'accueil. C'est mieux que rien, mais c'est aveugle à la majeure partie du parcours qui se joue ailleurs.
Le prompt unique est un thermomètre. La méthode 3 x 3 est un tableau de bord. Si vous voulez piloter votre visibilité IA aussi sérieusement que vous pilotez votre référencement classique, il vous faut le tableau de bord, pas le thermomètre seul. Et pour que le tableau de bord soit fiable, il faut savoir ce que chaque case mesure vraiment.
Commentaires
Aucun commentaire pour le moment. Soyez le premier à commenter !
Ajouter un commentaire