
Qu'est-ce qu'un moteur de recherche génératif ?
Un moteur de recherche génératif est une évolution des moteurs de recherche traditionnels qui s'appuie sur l'intelligence artificielle générative. Au lieu de se contenter de fournir une liste de liens hypertextes vers des pages web, il analyse, comprend et synthétise l'information provenant de multiples sources pour générer une réponse unique, cohérente et personnalisée.Cette réponse est souvent présentée sous la forme d'un résumé en haut des résultats, parfois enrichi de visuels ou de suggestions de questions complémentaires, permettant une expérience plus interactive et conversationnelle.
Quelle différence entre un SGE et un moteur de recherche classique ?
La différence fondamentale réside dans leur finalité et leur approche. Un moteur de recherche classique, comme Google dans son format traditionnel, utilise des algorithmes pour parcourir et indexer le contenu du web afin de trouver et de classer les ressources les plus pertinentes en réponse à une requête par mots-clés. Son but est de trouver de l'information existante.
Un moteur de recherche génératif, lui, a pour objectif de générer un nouveau contenu, une réponse directe, en se basant sur les informations qu'il a trouvées et comprises. Il transforme l'expérience de recherche d'une action de "chercher et cliquer" à une action de "demander et recevoir" une réponse directe.
Comment fonctionne un moteur de recherche génératif ?
Le fonctionnement d'un moteur de recherche génératif repose sur une architecture complexe qui combine plusieurs technologies de pointe. Le processus peut être décomposé en plusieurs grandes étapes, orchestrées principalement par un grand modèle de langage (LLM).
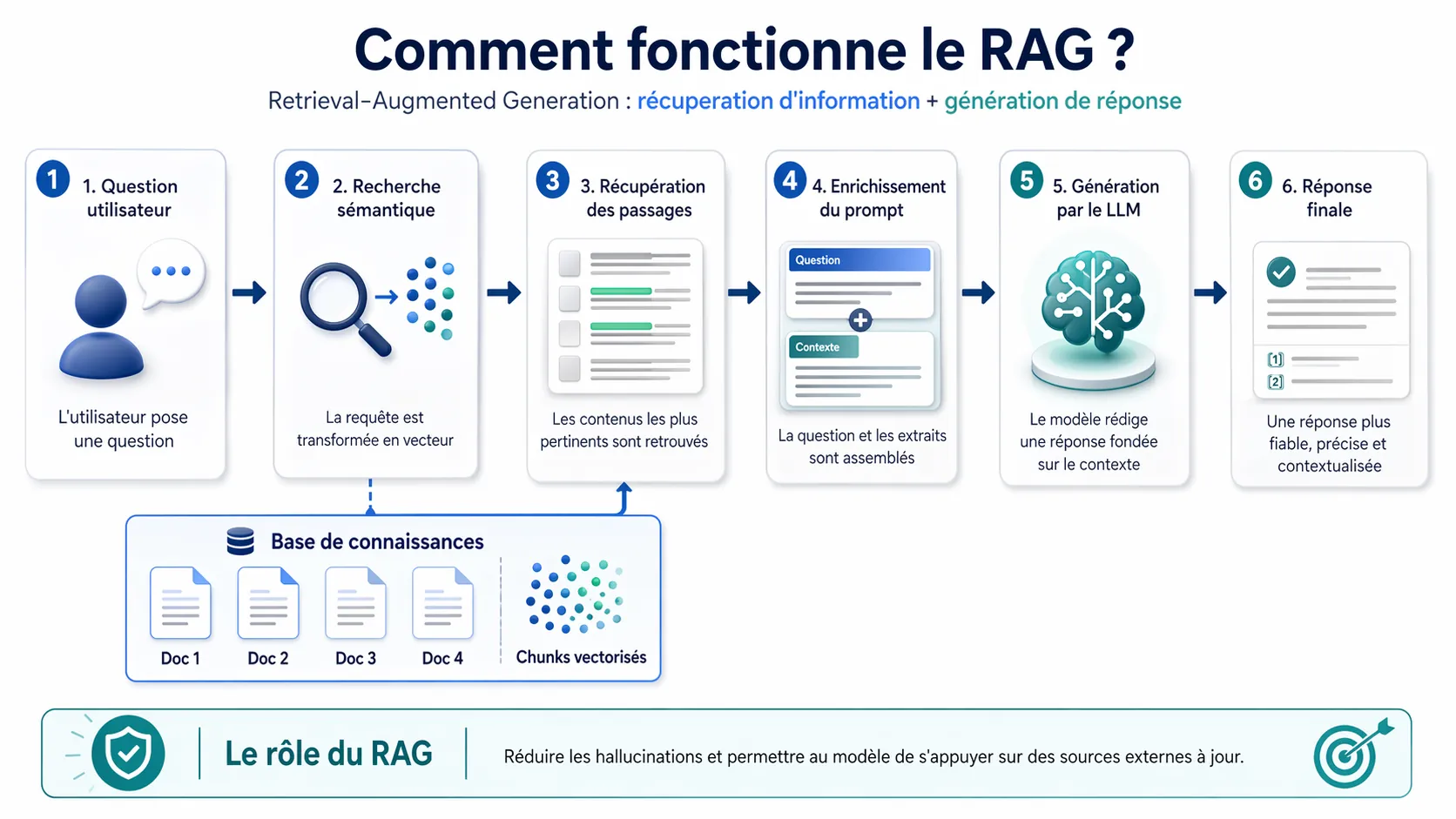
Comment un LLM décide-t-il de chercher à l'extérieur de ses connaissances ?
Un LLM est entraîné sur un immense corpus de données qui s'arrête à une date précise. Ses connaissances sont donc statiques et peuvent être obsolètes ou incomplètes. Le modèle doit donc "savoir ce qu'il ne sait pas". La décision de chercher des informations externes est cruciale et se déclenche dans plusieurs cas :
Détection de la nouveauté : La requête porte sur des événements très récents, postérieurs à sa date de fin d'entraînement.
Besoin de faits précis : La question exige des données factuelles, chiffrées ou des informations vérifiables qui demandent une haute précision.
Manque de confiance : Les algorithmes internes du LLM indiquent une faible probabilité d'avoir la bonne réponse dans ses données d'entraînement.
Requête spécifique à un domaine : La question concerne des informations privées ou très spécialisées (ex: base de connaissances d'une entreprise) sur lesquelles le modèle n'a pas été entraîné.
C'est là qu'intervient le mécanisme de Retrieval-Augmented Generation (RAG).
Qu'est-ce que le Retrieval-Augmented Generation (RAG) ?
Le RAG est une technique qui fusionne les capacités de génération de texte des LLM avec un processus de récupération d'information en temps réel. Plutôt que de se fier uniquement à sa mémoire interne, le LLM utilise le RAG pour aller chercher des informations fraîches et pertinentes dans une source de données externe.
Le processus se déroule en deux temps :
Récupération (Retrieval) : Le système identifie les documents ou passages les plus pertinents par rapport à la question de l'utilisateur dans sa base de connaissances externe.
Génération (Generation) : Le LLM intègre les informations récupérées dans son "contexte" et les utilise comme base pour formuler une réponse complète, précise et à jour.
Quel est le rôle des embeddings et des bases de données vectorielles ?
Pour que la phase de "Récupération" du RAG soit efficace, le moteur doit pouvoir comparer rapidement le sens de la question de l'utilisateur avec des milliards de documents. C'est ici qu'interviennent les embeddings et les bases de données vectorielles.
Embeddings : Un embedding (ou plongement lexical) est une représentation numérique d'un mot, d'une phrase ou d'un document entier sous la forme d'un vecteur de nombres. Ce vecteur capture le sens sémantique de l'information. Ainsi, des concepts sémantiquement proches, comme "chiot" et "chien", auront des vecteurs très similaires dans cet espace multidimensionnel.
Bases de données vectorielles : Ces bases de données sont spécifiquement conçues pour stocker et interroger efficacement ces embeddings. Lorsqu'un utilisateur pose une question, le moteur la convertit en un vecteur (embedding) puis recherche dans la base de données vectorielle les vecteurs de documents les plus proches ("voisins les plus proches"). C'est ce qu'on appelle la recherche de similarité ou la recherche sémantique.
Qu'est-ce que le Knowledge Graph ?
Le Knowledge Graph (graphe de connaissances) est une autre technologie essentielle qui agit comme le cerveau du moteur de recherche. Il ne s'agit pas de traiter les mots-clés comme de simples chaînes de caractères ("strings"), mais de les comprendre comme des objets du monde réel ("things") et de saisir les relations qui les unissent.
Un Knowledge Graph est une base de connaissances structurée où les informations sont organisées sous forme de nœuds (les entités : personnes, lieux, concepts) et d'arêtes (les relations entre ces entités). Par exemple, il relie "Léonard de Vinci" (entité) à "Mona Lisa" (entité) par la relation "a peint".
Pour un moteur de recherche génératif, le Knowledge Graph permet de :
Désambiguïser les requêtes : Comprendre si une recherche sur "Jaguar" concerne l'animal ou la marque de voiture.
Enrichir le contexte : Fournir des informations contextuelles directement dans la réponse générée.
Améliorer la pertinence : Aider le système RAG à trouver des informations plus pertinentes en comprenant les liens entre les concepts.
Exemples de différences de fonctionnement entre ChatGPT, Perplexity, Gemini et Grok
Pour illustrer ces concepts, examinons des exemples concrets de plateformes conversationnelles qui intègrent des éléments de moteurs de recherche génératifs.
Bien que ChatGPT d'OpenAI soit principalement un chatbot conversationnel basé sur un LLM, il intègre désormais des fonctionnalités de recherche web qui utilise le RAG pour citer des sources externes et fournir des réponses actualisées, mais il excelle surtout dans la génération créative et les tâches générales, avec un risque plus élevé d'hallucinations si les données ne sont pas vérifiées.
Perplexity AI, en revanche, est conçu comme un moteur de recherche pur, priorisant la précision et les citations systématiques de sources web. Il utilise des embeddings et RAG pour des réponses factuelles et rapides, idéal pour des recherches approfondies sur des sujets actuels, mais moins fort en créativité multimodale.
Google Gemini intègre le Knowledge Graph de Google et des capacités multimodales (texte, images, code), avec une emphase sur l'intégration à l'écosystème Google Search. Il est excellent pour des recherches contextuelles et visuelles, mais peut être plus conservateur dans ses réponses pour éviter les erreurs.
Enfin, Grok (d'xAI) se distingue par son accès en temps réel à des données de X (ex-Twitter) et au web, avec un ton humoristique et une capacité à gérer des requêtes complexes via des outils comme la recherche sémantique. Il est particulièrement fort pour des analyses en temps réel d'événements sociaux, mais limité en génération d'images comparé à Gemini ou ChatGPT.
FAQ : Les moteurs de recherche génératifs en bref
Qu'est-ce que Google SGE ?
La Search Generative Experience (SGE) est le nom de l'implémentation par Google d'un moteur de recherche génératif. Elle a été rebaptisée depuis AI Overviews. Elle intègre des résumés générés par IA et un mode conversationnel directement dans les résultats de recherche.
Les moteurs de recherche génératifs vont-ils remplacer le SEO ?
Non, mais ils le transforment profondément. Le SEO classique reste important, mais les stratégies doivent évoluer pour optimiser la visibilité au sein des réponses générées, ce qu'on appelle aujourd'hui le GEO (Generative Engine Optimization). Il devient crucial de produire des contenus factuels, bien structurés et crédibles.
Les informations générées sont-elles toujours fiables ?
Pas toujours. La qualité de la réponse dépend fortement de la qualité des informations récupérées par le système RAG. Si les sources externes sont inexactes, la réponse générée le sera aussi. La vérification des sources reste une compétence importante pour l'utilisateur.
Quels sont les principaux avantages d'un moteur de recherche génératif pour les utilisateurs ?
Les principaux avantages sont la rapidité d'obtention d'une réponse synthétisée, des résultats plus personnalisés et une expérience de recherche plus intuitive et interactive.
Quels sont les défis ?
Les défis incluent le risque de générer des informations incorrectes ("hallucinations"), les coûts informatiques élevés et la nécessité pour les entreprises d'adapter leurs stratégies de contenu pour rester visibles.


Commentaires
Aucun commentaire pour le moment. Soyez le premier à commenter !
Ajouter un commentaire