Qu'est-ce que le RAG (Retrieval Augmented Generation) ?
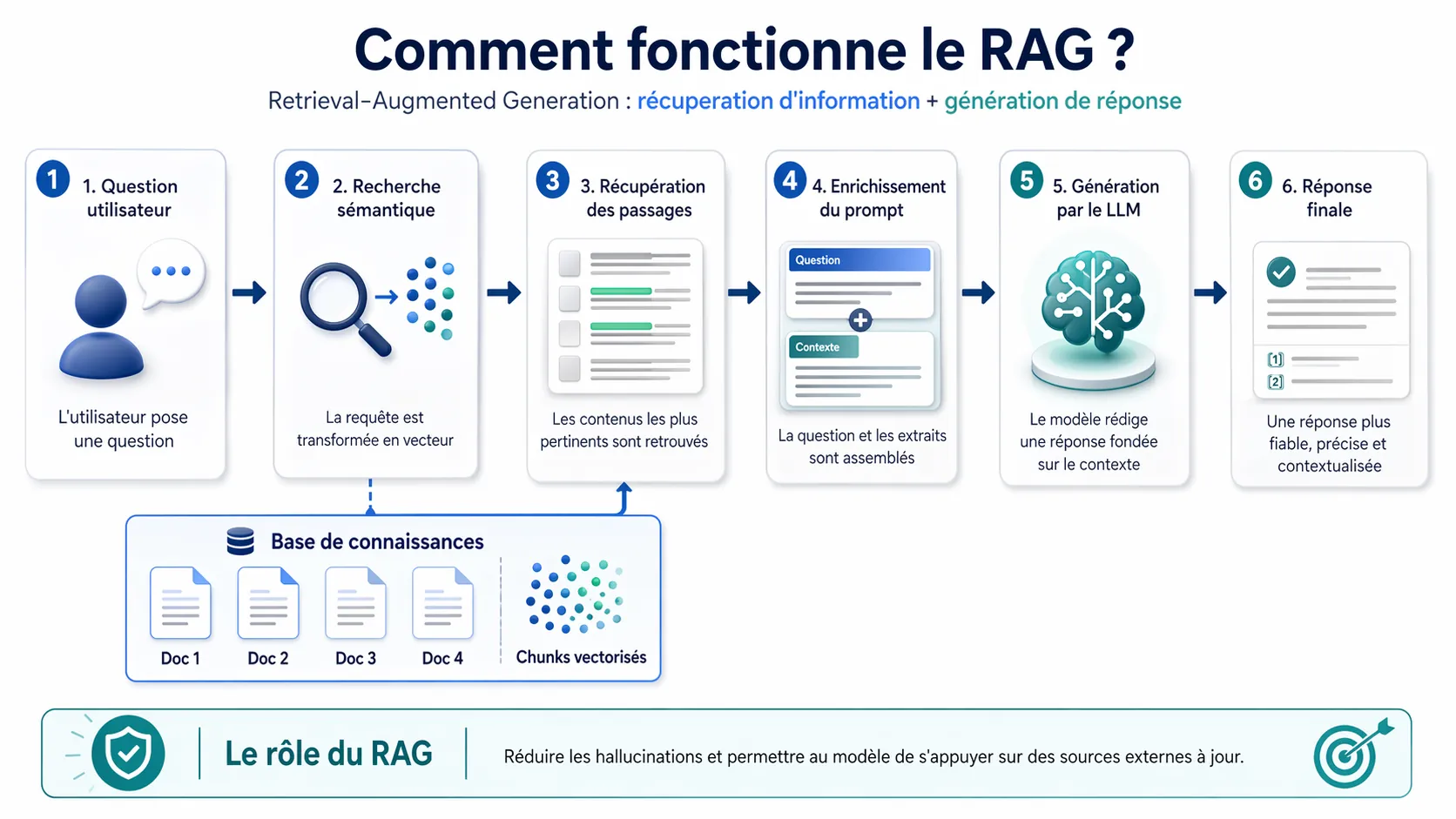
Le RAG, acronyme de Retrieval Augmented Generation (Génération Augmentée par Récupération en français), est une technique avancée d'intelligence artificielle qui révolutionne les capacités des grands modèles de langage (LLM). Cette approche novatrice permet aux systèmes d'IA générative de produire des réponses plus précises, factuelles et contextualisées en les connectant à des bases de données externes.
Concrètement, le RAG enrichit les réponses d'un modèle d'IA en lui permettant de consulter des sources d'information spécifiques en temps réel. Au lieu de se fier uniquement aux connaissances acquises lors de son entraînement, le modèle peut désormais rechercher et intégrer des données actualisées, spécialisées ou propres à une organisation avant de générer sa réponse.
Développée en 2020 par des chercheurs de Facebook AI Research (aujourd'hui Meta AI), cette méthode répond à l'un des défis majeurs des LLM : leur tendance aux "hallucinations" (génération d'informations incorrectes ou inventées) et leur limitation aux données d'entraînement souvent figées dans le temps.
Comment fonctionne le RAG : un processus en trois étapes clés
1. La phase de récupération (Retrieval)
Lorsqu'un utilisateur pose une question à un système RAG, celui-ci :
- Transforme la question en vecteurs numériques (embeddings) qui représentent mathématiquement son sens
- Effectue une recherche sémantique dans une base de données vectorielle pour identifier les informations les plus pertinentes
- Sélectionne les segments de contenu (chunks) dont la proximité sémantique avec la question est la plus élevée
Cette recherche s'appuie sur des calculs de similarité vectorielle (souvent par similarité cosinus) pour trouver les informations les plus proches du contexte de la question.
2. La phase d'augmentation (Augmentation)
Une fois les informations pertinentes identifiées :
- Le prompt initial est enrichi avec les données récupérées
- Un nouveau contexte étendu est créé, combinant la question originale et les informations spécifiques issues de la base de connaissances
- Le système prépare une instruction structurée pour le modèle de langage, lui indiquant comment utiliser ces informations
3. La phase de génération (Generation)
Enfin, le système :
- Transmet ce prompt augmenté au LLM qui peut désormais s'appuyer sur des informations ciblées
- Synthétise une réponse cohérente en intégrant intelligemment les données contextuelles fournies
- Produit un contenu précis et pertinent qui combine les capacités linguistiques du LLM avec les faits spécifiques récupérés
Cette architecture permet au modèle de répondre avec exactitude même sur des sujets absents de ses données d'entraînement ou nécessitant des informations très récentes.
Les composants essentiels d'un système RAG
Pour fonctionner efficacement, un système RAG s'appuie sur plusieurs éléments techniques indispensables :
- Une base de données vectorielle (Vector Store) : Entrepôt spécialisé où sont stockés les embeddings (représentations numériques) des documents et contenus textuels.
- Un modèle d'embedding : Algorithme qui convertit le texte en vecteurs numériques tout en préservant leur signification sémantique.
- Un mécanisme de recherche vectorielle : Système capable d'identifier rapidement les vecteurs les plus similaires à une requête donnée.
- Un grand modèle de langage (LLM) : Modèle d'IA générative comme GPT, Claude ou LLaMA qui assure la partie génération de texte.
- Un système de segmentation de texte : Outil qui découpe les documents sources en "chunks" (segments) de taille appropriée.
Le word embedding (ou enchâssement de mots) joue un rôle crucial dans ce processus, car il permet de traduire les concepts textuels en représentations mathématiques facilitant la recherche sémantique.
RAG vs LLM traditionnel : quelles différences fondamentales ?
| Caractéristique | LLM traditionnel | Système RAG |
|---|---|---|
| Source d'information | Limitée aux données d'entraînement | Données d'entraînement + bases de données externes |
| Mise à jour des connaissances | Nécessite un réentraînement complet | Mise à jour simple de la base de connaissances |
| Précision factuelle | Variable, risque d'hallucinations | Améliorée par l'ancrage dans des sources vérifiables |
| Contextualisation | Générique | Spécifique au domaine et personnalisable |
| Traçabilité | Difficile d'identifier la source | Sources des informations identifiables |
| Coût de déploiement | Élevé pour les modèles personnalisés | Plus économique (pas de réentraînement nécessaire) |
Contrairement aux LLM standards qui ne s'appuient que sur leurs paramètres internes, le RAG permet d'étendre dynamiquement les capacités du modèle sans nécessiter un réentraînement coûteux et complexe.
Les avantages majeurs du RAG pour l'IA générative
L'architecture RAG offre de nombreux bénéfices qui en font une approche de choix pour les applications professionnelles d'IA :
1. Précision et réduction des hallucinations
En ancrant les réponses dans des sources d'information vérifiables, le RAG réduit considérablement le risque d'hallucinations, ces réponses inventées ou inexactes que les LLM peuvent parfois produire. Cette fiabilité accrue est cruciale pour les applications professionnelles ou sensibles.
2. Actualisation des connaissances
Le RAG permet aux modèles d'accéder à des informations récentes qui n'existaient pas lors de leur entraînement. Cette capacité à rester à jour est particulièrement précieuse dans les domaines en évolution rapide comme la technologie, la médecine ou le droit.
3. Personnalisation et spécialisation
En connectant un LLM à des bases de connaissances spécifiques (documentation interne, publications scientifiques, rapports techniques), le RAG permet de créer des assistants IA spécialisés dans des domaines précis sans nécessiter de fine-tuning complexe.
4. Traçabilité et transparence
Le RAG facilite l'identification des sources d'information utilisées pour générer une réponse, améliorant ainsi la transparence et la responsabilité des systèmes d'IA. Cette traçabilité est essentielle pour les applications critiques ou réglementées.
5. Efficacité économique
Contrairement au réentraînement ou au fine-tuning d'un LLM, la mise à jour d'un système RAG ne nécessite que d'actualiser la base de connaissances externe, ce qui est généralement plus simple et moins coûteux.
6. Respect de la confidentialité
Les données sensibles peuvent rester dans un environnement contrôlé et n'être utilisées que pour la vectorisation et la recherche, sans jamais être intégrées directement dans le modèle de langage.
Applications pratiques du RAG dans différents secteurs
L'architecture RAG trouve des applications concrètes dans de nombreux domaines :
Service client et support technique
- Chatbots d'entreprise capables de répondre précisément aux questions en s'appuyant sur des manuels techniques, FAQ et bases de connaissances internes
- Assistants virtuels qui accèdent aux informations spécifiques des produits et services pour fournir une aide personnalisée
- Systèmes de triage qui orientent les demandes vers les bonnes ressources avec une compréhension contextuelle améliorée
Secteur juridique et conformité
- Assistants juridiques qui recherchent et synthétisent des précédents légaux, jurisprudences et textes de loi spécifiques
- Outils de vérification de conformité capables d'analyser des documents à l'aune de réglementations précises et actualisées
- Systèmes de rédaction assistée pour la création de contrats ou documents juridiques
Santé et recherche médicale
- Assistants diagnostiques qui intègrent les dernières recherches médicales et guidelines cliniques
- Outils de recherche scientifique capables de synthétiser des études récentes sur des sujets précis
- Systèmes d'aide à la décision pour les professionnels de santé
Éducation et formation
- Tuteurs personnalisés adaptant leurs explications aux ressources pédagogiques spécifiques d'un cours
- Systèmes de questions-réponses sur des corpus éducatifs spécialisés
- Assistants de recherche académique pour faciliter l'exploration de publications scientifiques
Création de contenu et SEO
L'utilisation du RAG transforme également la création de contenu optimisé pour le référencement :
- Analyse contextuelle plus fine des sujets et de leur couverture
- Identification précise des questions que se posent les internautes sur un sujet
- Production de contenu plus complet et mieux documenté
- Enrichissement thématique grâce à l'exploration de sources diversifiées
Découvrez mon article sur comment construire un RAG SEO.
Défis et limitations actuelles du RAG
Malgré ses nombreux avantages, le RAG présente certaines limitations qu'il est important de considérer :
Complexité technique
La mise en place d'un système RAG efficace nécessite une expertise technique pour :
- L'indexation optimale des documents
- La création et la maintenance de la base vectorielle
- L'intégration harmonieuse avec le LLM
Qualité des sources
La pertinence des réponses dépend directement de la qualité des sources indexées. Des documents erronés ou biaisés dans la base de connaissances se répercuteront dans les réponses générées.
Coûts d'infrastructure
Le stockage et la gestion des bases de données vectorielles peuvent nécessiter des ressources informatiques conséquentes, particulièrement pour de grands corpus de documents.
Intégration des informations
Le LLM peut parfois ne pas exploiter parfaitement les informations fournies par le système de récupération, créant un décalage entre les données récupérées et la réponse générée.
Comment optimiser un système RAG
Pour maximiser l'efficacité d'une architecture RAG, plusieurs bonnes pratiques peuvent être mises en œuvre :
Optimisation de la segmentation
La taille et la structure des "chunks" (segments de texte) sont cruciales pour l'efficacité du système. Une segmentation trop fine peut perdre le contexte, tandis qu'une segmentation trop grossière peut diluer la pertinence.
Sélection de modèles d'embedding performants
La qualité des représentations vectorielles détermine largement la précision de la recherche sémantique. Le choix d'un modèle d'embedding adapté au domaine et à la langue est essentiel.
Enrichissement des métadonnées
L'ajout de métadonnées structurées (auteur, date, catégorie, source...) aux documents indexés permet d'affiner les recherches et de contextualiser davantage les informations.
Filtrage intelligent
L'implémentation de mécanismes de filtrage (par pertinence, fraîcheur, autorité...) aide à sélectionner les informations les plus appropriées pour chaque requête.
Évaluation continue
La mise en place de métriques d'évaluation (précision, pertinence, satisfaction utilisateur...) permet d'identifier les points d'amélioration et d'ajuster le système.
L'avenir du RAG dans l'écosystème de l'IA générative
Le RAG représente une évolution significative pour l'IA générative et son intégration dans des contextes professionnels. Les tendances futures incluent :
- Systèmes multi-agents combinant plusieurs modèles spécialisés pour des tâches complémentaires
- RAG multimodal intégrant des sources d'information diverses (texte, image, audio, vidéo)
- Architectures hybrides mêlant RAG et fine-tuning pour des performances optimales
- Systèmes d'auto-évaluation capables d'améliorer continuellement leurs réponses
À mesure que les techniques d'IA évoluent, le RAG s'impose comme une approche incontournable pour créer des systèmes d'intelligence artificielle à la fois puissants, fiables et adaptés aux exigences du monde réel.
FAQ sur le RAG (Retrieval Augmented Generation)
Quelle est la différence principale entre un LLM classique et un système RAG ?
Un LLM classique s'appuie uniquement sur ses connaissances acquises lors de l'entraînement, tandis qu'un système RAG peut consulter des sources externes en temps réel pour enrichir ses réponses avec des informations actualisées et spécifiques.
Le RAG élimine-t-il complètement les hallucinations des modèles d'IA ?
Le RAG réduit significativement les hallucinations mais ne les élimine pas entièrement. La qualité des réponses dépend de la pertinence des sources indexées et de la capacité du système à récupérer les informations appropriées.
Est-il possible d'implémenter un RAG sur n'importe quel type de LLM ?
En théorie, oui. Le RAG est une architecture qui peut être appliquée à divers modèles de langage, qu'ils soient open-source ou propriétaires, à condition d'avoir accès à leurs API ou à leur code.
Quels types de documents peut-on intégrer dans une base de données RAG ?
Pratiquement tous les types de documents textuels peuvent être intégrés : articles, rapports, documentation technique, FAQ, emails, transcriptions, livres, etc. L'important est qu'ils soient convertissables en format texte pour la vectorisation.
Le RAG nécessite-t-il des ressources informatiques importantes ?
Les besoins en ressources dépendent principalement de la taille du corpus de documents et du volume de requêtes à traiter. Des solutions optimisées existent pour les différentes échelles de déploiement, des applications personnelles aux systèmes d'entreprise.
Comment mesurer l'efficacité d'un système RAG ?
L'efficacité peut être évaluée selon plusieurs critères : précision factuelle des réponses, pertinence par rapport à la question, fraîcheur des informations, temps de réponse, et satisfaction des utilisateurs.
Le RAG est-il adapté pour toutes les langues ?
Le RAG peut fonctionner dans n'importe quelle langue, mais son efficacité dépendra de la disponibilité de bons modèles d'embedding et de LLM pour la langue concernée, ainsi que de la qualité des documents sources dans cette langue.
Comment gérer les informations contradictoires dans un système RAG ?
La gestion des contradictions est un défi important. Les approches incluent la priorisation des sources selon leur fiabilité, la présentation des différentes perspectives à l'utilisateur, ou l'implémentation de mécanismes de résolution de conflits basés sur des critères prédéfinis.




Commentaires
Aucun commentaire pour le moment. Soyez le premier à commenter !
Ajouter un commentaire