
Définition d'une entité nommée
Il n'existe pas de consensus réel sur la définition d'entité nommée puisqu'elle est souvent dépendante de son champ d'application qui peut être multiple et varié.
Toutefois, dans le traitement automatique du langage naturel et la recherche du sens d'un texte ou d'une requête, une entité nommée peut être définie comme un objet textuel.
Il peut s'agir d'un mot ou d'un groupe de mots, catégorisable dans des classes comme les lieux, les personnes ou les orgnaisations. A ces entités, nous pouvons rattacher des caractéristiques ou des attributs.
Qu'est-ce que la reconnaissance d'entités nommées ?
La reconnaissance d'entités nommées (ou NER pour Named Entity Recognition) désigne le processus par lequel un système identifie automatiquement dans un texte, des objets sémantiques appelés entités. Il peut s'agir de personnes, d'organisations, de lieux, de dates, de produits, de lois... En d'autres termes, le NER vise à détecter et classer des fragments textuels porteurs de sens dans des catégories prédéfinies.
Par exemple, dans la phrase : "Marie Curie a reçu le prix Nobel de physique en 1903".
Un système NER extrait :
- Marie Curie : Person ;
- Prix Nobel de physique : Award ;
- 1903 : Date.
La force du NER réside dans sa capacité à structurer l'information sous forme de triplets sémantiques (ou triples RDF) :
- Sujet : Marie Curie ;
- Prédicat : a reçu ;
- Objet : Prix Nobel de physique.
Ces triplets sont les briques de base des graphes de connaissances (knowledge graphs) comme celui de Google. Une fois les entités reconnues, elles sont liées entre elles via des relations, ce qu'on appelle l'entity linking ou entity desambiguation. Cela permet au moteur d'associer un mot à son référent unique, même en cas d'ambiguïté.
Aux origines du concept de NER
Le concept de reconnaissance des entités nommées au sein d'un document textuel est apparu dans le milieu des années 90. Il est aujourd'hui un élément incontournable dans le traitement automatique du langage naturel.
Selon une étude menée par Microsoft en 2010, entre 20 et 30 % des requêtes soumises dans Bing étaient des entités nommées à part entière. Dans le même temps, 71% d'entre elles contenaient au moins une entité nommée dans la question posée.
On comprend alors tout l'intérêt pour un moteur de recherche de constituer une gigantesque base de données d'entités nommées. Elle permet de catégoriser des requêtes et des pages web, de simplifier l'extraction de la bonne information et d'améliorer la pertinence des résultats.
2010, c'est également l'année où google rachète Metaweb, une société connue pour avoir développé Freebase, une base de données de plusieurs millions d'entités nommées.
C'est avec cette base de données qui rassemble aujourd'hui 500 milliards de faits au sujet de 5 milliards d' entités selon les dernières informations données par Google en 2020, que le moteur de recherche a déployé son Knowledge Graph (ou arbre de connaissances) à partir de 2012.
Le Knowledge Graph en action : l'exemple de Kylian Mbappé
Prenons un exemple concret : lorsque vous tapez Kylian Mbappé dans Google, un encart informatif apparaît. Aussi appelé Knowledge Panel, il se positionne à droite sur desktop ou en haut sur mobile. Cet encart est une extraction directe du Knowledge Graph de Google. Il affiche une synthèse des principales informations liées à l’entité Kylian Mbappé, reconnue comme une Personne par les algorithmes de NER.
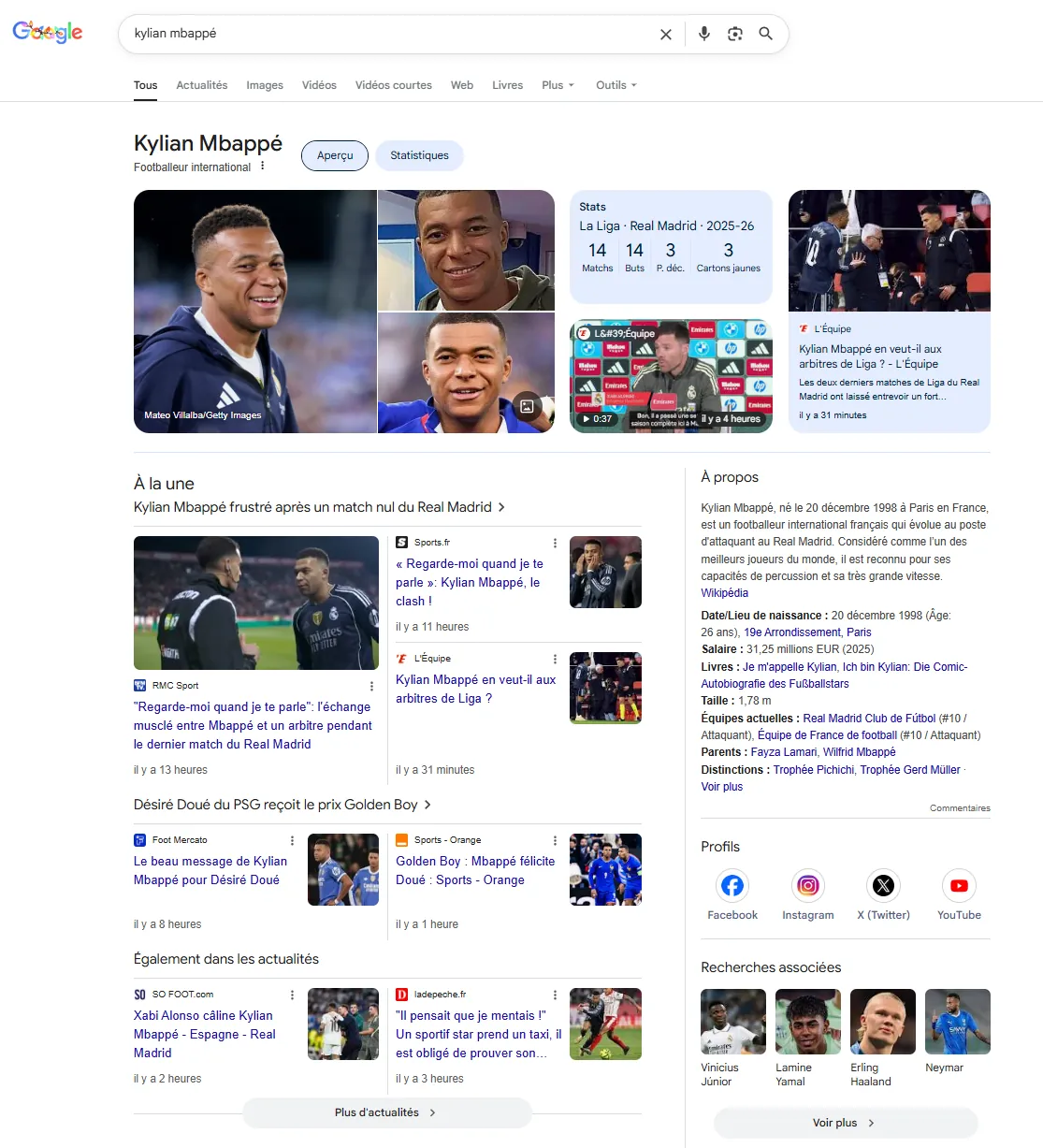 Parmi les attributs visibles :
Parmi les attributs visibles :
- Sa date et son lieu de naissance ;
- Son club actuel ;
- Son poste (attaquant) ;
- Les trophées remportés ;
- Son parcours en équipe de France ;
- Ses statistiques ;
- Ses comptes sociaux.
Ces informations ne proviennent pas d’un seul site web, mais sont agrégées et structurées à partir de nombreuses sources croisées (presse, Wikipédia, données structurées, etc.), puis organisées sous forme de triplets sémantiques. Ces triplets permettent à Google de comprendre la nature de la relation entre les entités, et de naviguer dans son graphe de connaissances pour étendre la réponse potentielle.
On comprend alors que le Knowledge Graph fonctionne comme une base relationnelle dynamique, où chaque entité est liée à d’autres entités par des prédicats. C’est cette structure en graphe qui permet au moteur de recherche d’offrir une vue d’ensemble cohérente, connectée et intelligible aux utilisateurs, sans qu’ils aient à naviguer entre plusieurs sites.
Entité et prédiction de requête
C'est notamment grâce à l'extraction des entités nommées et au Knowledge Graph qu'a commencé à émerger la notion de moteur de réponse au sujet de Google.
En apportant directement des informations liées aux propriétés d'une entité nommée dans ses pages de résultats, Google va jusqu'au point où il tente de prédire quelle sera la prochaine requête de l'utilisateur. Tout simplement parce qu'il se concentre sur la véritable intention de recherche de l'internaute, c'est à dire tous les sujets qui sont connexes à sa requête principale.
En effet, si l'internaute tape Kylian Mbappé dans la barre de recherche, peut-être souhaite-t-il en réalité avoir des informations sur sa famille, sur son âge, sur un ancien club, etc. Le Knowledge Graph pourrait potentiellement répondre à cette question que l'internaute n'a pas su poser.
Basé sur une série de statistiques liées aux signaux utilisateurs, Google renvoie ainsi directement dans son Knowledge Graph des recherches associées permettant bien souvent à l'internaute de ne même pas avoir besoin de formuler lui-même sa question.
Les défis de la reconnaissance des entités nommées
Il faut cependant savoir que la reconnaissance des entités nommées se heurte à plusieurs défis de taille parmi lesquels nous pouvons citer la désambiguïsation lexicale et l'évolution des entités.
La désambiguïsation lexicale (Word Sens Disambiguation)
Un même terme peut en effet avoir plusieurs sens différents. On dit alors qu'il est polysémique. L'exemple classique qu'on donne en SEO est le terme "jaguar" qui peut à la fois désigner l'animal sauvage mais également la marque de voitures de luxe.
Dans le cadre d'une recherche d'informations, le moteur doit comprendre le sens du terme "jaguar". Cette entité peut avoir pour type le nom d'une organisation ou le nom d'un animal.
Lorsque l'utilisateur utilise le terme "jaguar" dans sa requête, le moteur de recherche analyse le contexte. Il peut par exemple s'appuyer sur les mots qui entourent "jaguar", afin de comprendre le besoin réel de l'internaute et de lui renvoyer les résultats les plus pertinents.
Un scoring sera par ailleurs mis en place afin de déterminer la probabilité qu'un utilisateur recherche plutôt telle ou telle information. C'est le cas lorsqu'il tape une requête de type "jaguar" dans le moteur de recherche.
Dans cet exemple, Google renvoie majoritairement des résultats liés à la marque de voiture pour la requête "jaguar". Il a déterminé, en fonction de nombreux paramètres, qu'il s'agissait de l'intention la plus probable.
Parmi ces paramètres figurent notamment la géolocalisation de l'internaute et son historique de recherche. En l'absence de précision, Google juge plus probable une recherche sur la marque de voiture que sur l'animal.
Cette probabilité n'étant cependant pas sûr à 100%, quelques résultats sur la page de Google renvoie vers le félin.
Le moteur de recherche propose aussi à l'internaute de préciser sa recherche sous la forme de deux onglets. L'un renvoie vers les résultats "jaguar entreprise", l'autre vers les résultats "jaguar animal".
A noter par ailleurs que c'est dans l'objectif de mieux comprendre le sens des pages web que Google, Bing et Yahoo ont lancé conjointement le projet schema.org en 2011. Ce projet vise en effet à proposer un schéma de micro données unifié afin de labelliser ou baliser certains termes pour supprimer les ambiguïtés lexicales et faciliter ainsi le travail des robots des moteurs de recherche.
L'évolution des entités
Le second défi auquel doivent faire face les moteurs de recherche utilisant la reconnaissance des entités nommées est celui de la mise à jour de ces entités nommées. En effet un objet textuel peut ne pas être une entité à un instant t mais le devenir par la suite. Alain Delon, avant d'être un acteur célèbre, n'était pas une entité au sens ou Google l'entend, c'est à dire un objet issu du monde réel unique et distinguable cité à de très nombreuses reprises, dans de très nombreux documents différents.
De plus, les propriétés d'une entité peuvent évoluer avec le temps. Par exemple, Yannick Noah était d'abord un sportif de haut niveau, joueur de tennis français vainqueur de Roland Garros, avant de devenir capitaine de Coupe Davis, puis chanteur à succès.
Toute la difficulté réside donc pour Google dans le fait de tenir constamment à jour sa base de données d'entités qui s'élargit avec le temps, pour renvoyer constamment les résultats les plus pertinents à l'utilisateur en recherche d'informations.
Comment optimiser vos contenus pour les entités nommées ?
Comprendre ce qu'est une entité nommée est une première étape, mais savoir optimiser vos contenus pour qu'ils soient parfaitement interprétés par Google, et désormais les moteurs génératifs comme ChatGPT ou Perplexity, en est une autre. Voici 3 leviers concrets pour aider les moteurs de recherche à connecter votre contenu au Knowledge Graph.
1. Travaillez le champ sémantique et les co-occurrences
Pour qu'un algorithme de NER (Named Entity Recognition) identifie correctement une entité sans ambiguïté, il a besoin de contexte. Si vous parlez de "Jaguar", entourez votre mot-clé d'attributs spécifiques :
- Pour l'animal : évoquez son habitat (forêt amazonienne), sa famille (félin), son régime alimentaire.
- Pour la voiture : évoquez le modèle, le moteur, la marque de luxe, le constructeur.
Plus vous fournirez de triplets sémantiques clairs (Sujet > Verbe > Objet) dans vos phrases, plus il sera facile pour Google (et les LLM) d'extraire les relations entre les entités.
2. Utilisez les données structurées (Schema.org)
C'est le moyen le plus direct de "parler" aux robots. L'utilisation du balisage Schema.org permet de déclarer explicitement de quelle entité il s'agit.
L'attribut le plus puissant pour cela est la propriété sameAs. Elle permet de dire à Google : "L'entité dont je parle ici est exactement la même que celle décrite sur cette page Wikipédia ou cette fiche Wikidata".
Exemple de code JSON-LD pour désambiguïser une personne :
"sameAs": [
"https://fr.wikipedia.org/wiki/Votre_Page",
"https://www.wikidata.org/wiki/Q123456",
"https://twitter.com/votre_profil"
]

3. Testez vos contenus avec l'API Google NLP
Comment savoir si Google a bien compris votre texte ? Google met à disposition une démo gratuite de son API Natural Language.
Copiez-collez un paragraphe de votre article dans cet outil. Il vous montrera :
- Les entités détectées (Personnes, Lieux, Organisations...).
- Le score de saillance (l'importance de l'entité dans le texte).
- Le lien vers la page Wikipédia associée (preuve qu'il a bien identifié l'entité unique).
C'est un excellent test pour vérifier si votre rédaction est suffisamment claire pour les algorithmes avant publication.

Commentaires
Aucun commentaire pour le moment. Soyez le premier à commenter !
Ajouter un commentaire