
Le site web envisagé comme un corpus vectoriel interconnecté
Un site web n'est pas une simple collection de fichiers HTML posés sur un serveur : c'est un corpus vivant. Si vous structurez intelligemment cette base de connaissances, elle devient immédiatement exploitable par un grand modèle de langage connecté à votre infrastructure.
Il ne s'agit pas ici de concevoir une démonstration technique de plus pour amuser la galerie. Ce tuto a vocation à vous aider à construire un outil de production capable de répondre à des questions que les outils SEO classiques ne savent pas traiter :
- Quelles pages souffrent d'un déficit de liens internes entrants ?
- Quels articles partagent une proximité sémantique forte et doivent être reliés pour renforcer un cocon ?
- Quelles ancres exactes pointent vers une URL spécifique ?
- Quelles pages s'éloignent dangereusement du centroïde sémantique du site ?
- Quels contenus ont été modifiés depuis le dernier passage, exigeant une mise à jour des vecteurs sans pour autant tout réencoder ?
Le code source complet pour déployer cette architecture est accessible ici : Dépôt GitHub - Semantic Site RAG.
Pourquoi PostgreSQL et pgvector surclassent les bases vectorielles dédiées
Choisir une base de données vectorielle pure pour analyser le référencement d'un site est une erreur d'architecture. Le SEO est une affaire de relations : une URL pointe vers une autre via une ancre précise, au sein d'une structure parent-enfant.
Supabase résout ce problème en combinant la puissance relationnelle de PostgreSQL, une API d'accès rapide et l'extension pgvector. Il est ainsi possible de stocker des types de données radicalement différents au même endroit. D'un côté, des tables SQL classiques pour les URLs, les balises meta, les codes de réponse HTTP et les liens. De l'autre, des représentations vectorielles de nos contenus (les embeddings) pour mesurer la distance sémantique entre deux pages ou deux paragraphes. Un simple script Python assure la synchronisation, tandis que le connecteur de votre modèle de langage ou de votre plateforme conversationnelle (il existe des connecteurs Supabase natifs dans ChatGPT, Claude, ou encore Le Chat de Mistral AI) interroge l'ensemble sans friction.
Modéliser à double échelle : la page et le chunk
L'analyse sémantique d'un site exige deux niveaux de lecture bien distincts sous peine de générer des faux positifs. C'est pourquoi notre structure de données sépare l'entité globale de ses composants.
L'embedding de la page complète offre une vue macroscopique. Il sert à définir la thématique générale d'une URL, à calculer le centre de gravité sémantique du site et à détecter les hors-sujets. Mais il s'avère trop imprécis pour identifier un point d'insertion précis de lien interne.
C'est là que le découpage en blocs (les chunks) intervient. En fragmentant un texte de deux mille mots en segments de taille contrôlée, nous pouvons localiser le paragraphe exact qui justifie la création d'un lien hypertexte.
Découvrez mon article sur pourquoi structurer son contenu pour le chunking sémantique.
La structure de la base de données : SQL de déploiement
La configuration de la base de données s'effectue en injectant trois scripts SQL directement dans l'éditeur de requêtes de Supabase.
Étape 1 : Activer le moteur vectoriel
Nous devons d'abord indiquer à PostgreSQL qu'il doit manipuler des vecteurs de haute dimension. Exécutez le script d'initialisation de l'extension :
-- sql/001_enable_pgvector.sql
create extension if not exists vector;
Étape 2 : Définir le schéma relationnel
Le cœur du système repose sur quatre tables interconnectées. La table des pages enregistre les métadonnées et l'empreinte de sécurité (le hash), la table des blocs stocke les fragments de texte, la table des liens modélise le graphe du site, et la table de suivi enregistre l'historique des opérations de crawl.
Exécutez la structure suivante :
-- sql/002_create_tables.sql
-- Table principale des pages du site
create table if not exists public.rag_pages (
id uuid default gen_random_uuid() primary key,
url text unique not null,
title text,
meta_description text,
content text,
content_hash text,
embedding vector(1536), -- Dimension adaptée au modèle text-embedding-3-small
pagerank_score float8 default 0.0,
in_sitemap boolean default true,
created_at timestamp with time zone default timezone('utc'::text, now()) not null,
updated_at timestamp with time zone default timezone('utc'::text, now()) not null
);
-- Table des fragments de contenu (chunks)
create table if not exists public.rag_chunks (
id uuid default gen_random_uuid() primary key,
page_id uuid references public.rag_pages(id) on delete cascade not null,
chunk_index integer not null,
content text not null,
embedding vector(1536),
created_at timestamp with time zone default timezone('utc'::text, now()) not null
);
-- Table des liens internes et de leurs ancres
create table if not exists public.rag_links (
id uuid default gen_random_uuid() primary key,
source_url text not null,
target_url text not null,
anchor_text text,
is_nofollow boolean default false,
created_at timestamp with time zone default timezone('utc'::text, now()) not null,
unique (source_url, target_url, anchor_text)
);
-- Suivi des lancements de synchronisation
create table if not exists public.rag_refresh_runs (
id uuid default gen_random_uuid() primary key,
started_at timestamp with time zone default timezone('utc'::text, now()) not null,
completed_at timestamp with time zone,
urls_processed integer default 0,
urls_updated integer default 0
);Étape 3 : Déployer les fonctions de recherche vectorielle
Pour calculer la similarité cosinus directement dans la base de données sans rapatrier les données en mémoire locale, nous créons deux fonctions SQL. Elles renvoient les éléments les plus proches d'un vecteur cible.
Exécutez ce troisième bloc :
-- sql/003_create_match_functions.sql
-- Recherche de proximité au niveau des pages complètes
create or replace function match_rag_pages (
query_embedding vector(1536),
match_threshold float,
match_count int
)
returns table (
id uuid,
url text,
title text,
similarity float
)
language sql stable
as $$
select
id,
url,
title,
1 - (embedding <=> query_embedding) as similarity
from public.rag_pages
where 1 - (embedding <=> query_embedding) > match_threshold
order by embedding <=> query_embedding
limit match_count;
$$;
-- Recherche de proximité chirurgicale au niveau des paragraphes (chunks)
create or replace function match_rag_chunks (
query_embedding vector(1536),
match_threshold float,
match_count int
)
returns table (
id uuid,
page_id uuid,
url text,
content text,
similarity float
)
language sql stable
as $$
select
c.id,
c.page_id,
p.url,
c.content,
1 - (c.embedding <=> query_embedding) as similarity
from public.rag_chunks c
join public.rag_pages p on c.page_id = p.id
where 1 - (c.embedding <=> query_embedding) > match_threshold
order by c.embedding <=> query_embedding
limit match_count;
$$;Étape 4 : Sécuriser vos tables avec Row Level Security
Par défaut, toute table créée dans le schéma public de Supabase est exposée via l'API PostgREST. Si une clé anon est ensuite intégrée dans un frontend ou une application cliente, les tables rag_pages, rag_chunks et rag_links deviennent lisibles, voire modifiables, par n'importe quel visiteur.
Notre script d'ingestion utilise la clé service_role côté serveur, qui ignore les politiques RLS. Vous pouvez donc activer Row Level Security sur ces tables sans créer la moindre politique d'accès : le script continuera à fonctionner normalement, tandis que toute tentative de lecture ou d'écriture depuis l'API publique sera bloquée par défaut.
Exécutez ce script de durcissement immédiatement après le déploiement du schéma :
-- sql/004_enable_rls.sql
-- Active Row Level Security sur les tables RAG
alter table public.rag_pages enable row level security;
alter table public.rag_chunks enable row level security;
alter table public.rag_links enable row level security;
alter table public.rag_refresh_runs enable row level security;
-- Pas de politique = aucun accès depuis anon ou authenticated.
-- Le service_role utilisé par notre crawler conserve un accès complet.Vérification : dans le tableau de bord Supabase, ouvrez l'onglet Authentication → Policies. Chaque table doit afficher l'icône RLS active et aucune politique attachée. Si vous prévoyez plus tard d'exposer un tableau de bord public alimenté par ces données, vous devrez ajouter explicitement des politiques create policy pour autoriser des lectures contrôlées — jamais d'écritures depuis la clé anon.
La documentation officielle Supabase sur Row Level Security détaille la rédaction de politiques avancées si vous avez ce besoin.
Configuration de l'environnement de crawl
La mise en place du script d'ingestion demande une préparation rigoureuse de vos variables d'accès.
Clonez d'abord le projet de base et préparez votre environnement d'exécution :
git clone https://github.com/JuJu78/semantic-site-rag.git
cd semantic-site-rag
python -m venv .venv
# Activation - Windows
.venv\Scripts\activate
# Activation - Linux/macOS
source .venv/bin/activate
pip install -r requirements.txtDupliquez le fichier .env.example sous le nom .env. Vous devez renseigner les clés d'accès à Supabase et à votre fournisseur de modèles de langage :
OPENAI_API_KEY=sk-proj-...
OPENAI_EMBEDDING_MODEL=text-embedding-3-small
SUPABASE_URL=https://votre-projet.supabase.co
SUPABASE_SERVICE_ROLE_KEY=votre-cle-service-role
SITE_BASE_URL=https://votre-site.com
CHUNK_SIZE=1200
CHUNK_OVERLAP=180
REQUEST_TIMEOUT=30
CRAWL_DELAY_SECONDS=1.0
USER_AGENT=SemanticSiteRAG/0.1 (+https://votre-site.com)Note stratégique : la clé service_role possède des privilèges d'écriture globaux sur votre base de données. Ne la committez jamais sur un dépôt public.
L'ingestion des données et l'évitement des coûts inutiles
Le principal défaut des scripts de RAG amateur est de recalculer les vecteurs à chaque exécution. Pour un site de mille pages, cette pratique se traduit par une consommation absurde de requêtes API.
Notre script de synchronisation contourne ce problème en utilisant une empreinte MD5 du texte de la page. Lors du crawl, le script télécharge le contenu HTML brut, extrait la zone de texte principale (en ignorant les menus, le pied de page et les barres latérales), puis calcule son empreinte.
[Page Web] -> Extraction du texte -> Calcul du Hash (MD5)
|
Existe en base ?
/ \
(Oui) (Non)
/ \
Hash identique ? Générer Embedding & Chunks
/ \ Enregistrer en base
(Ignorer) (Mettre à jour)Si le hash calculé correspond à celui stocké en base de données, l'insertion est ignorée. Dans le cas contraire, les anciens blocs associés à cette URL sont nettoyés et une nouvelle passe d'embedding est lancée.
Pour démarrer la première indexation complète de votre sitemap XML, lancez la commande suivante :
python scripts/ingest_site.py --sitemap https://votre-site.com/sitemap.xmlSi vous venez de publier un nouvel article et souhaitez l'intégrer immédiatement sans re-parcourir le sitemap, ciblez directement son URL :
python scripts/ingest_site.py --url https://votre-site.com/le-nouvel-articleExploiter le potentiel sémantique
Une fois les données structurées et les relations stockées, vous disposez d'un levier d'optimisation puissant.
Calculer la force du maillage avec le PageRank interne
Le score de PageRank interne ne représente pas l'autorité théorique attribuée par Google, mais la répartition réelle de la popularité au sein de votre propre architecture de liens.
Exécutez le script d'analyse structurelle :
python scripts/compute_pagerank.pyCette commande applique l'algorithme de PageRank sur la table rag_links. Les pages qui reçoivent beaucoup de liens qualitatifs obtiennent un score élevé, tandis que les pages isolées sombrent vers zéro.
Traquer les anomalies structurelles
En croisant le PageRank avec la position sémantique de vos pages, vous identifiez instantanément les défauts de votre structure. Lancez l'audit global :
python scripts/audit_site.py --min-incoming 3Le rapport généré dans reports/site_audit.json met en lumière un concept mathématique crucial : le centroïde sémantique. Il s'agit de la moyenne vectorielle de toutes les pages de votre site, qui représente l'identité thématique globale de votre domaine.
Une page située à une distance excessive du centroïde sémantique est une anomalie. Soit le script d'extraction a récupéré du code parasite, soit la page traite d'un sujet hors-thème qui risque de diluer la cohérence globale de votre site, soit elle est totalement déconnectée du reste du catalogue.
Proposer des maillages pertinents avant publication
La meilleure intégration d'un lien se fait lors de l'écriture du texte, pas après coup sous la contrainte d'un outil d'audit.
Lorsque vous rédigez un nouvel article sous forme de brouillon au format Markdown, vous pouvez interroger votre base Supabase pour connaître les meilleures opportunités de maillage à intégrer dans ce texte avant même qu'il ne soit en ligne.
Lancez le script d'analyse prédictive :
python scripts/find_link_opportunities.py --text-file drafts/nouvel-article.mdLe script calcule l'embedding temporaire de votre brouillon et interroge la table rag_chunks dans Supabase. Il génère un rapport structuré dans reports/link_opportunities.json.
La force de cette approche est que votre texte de travail n'est pas inséré en base : il sert simplement de sonde sémantique pour trouver les paragraphes existants qui partagent une affinité sémantique étroite avec vos nouveaux écrits.
Piloter son SEO par le dialogue sémantique
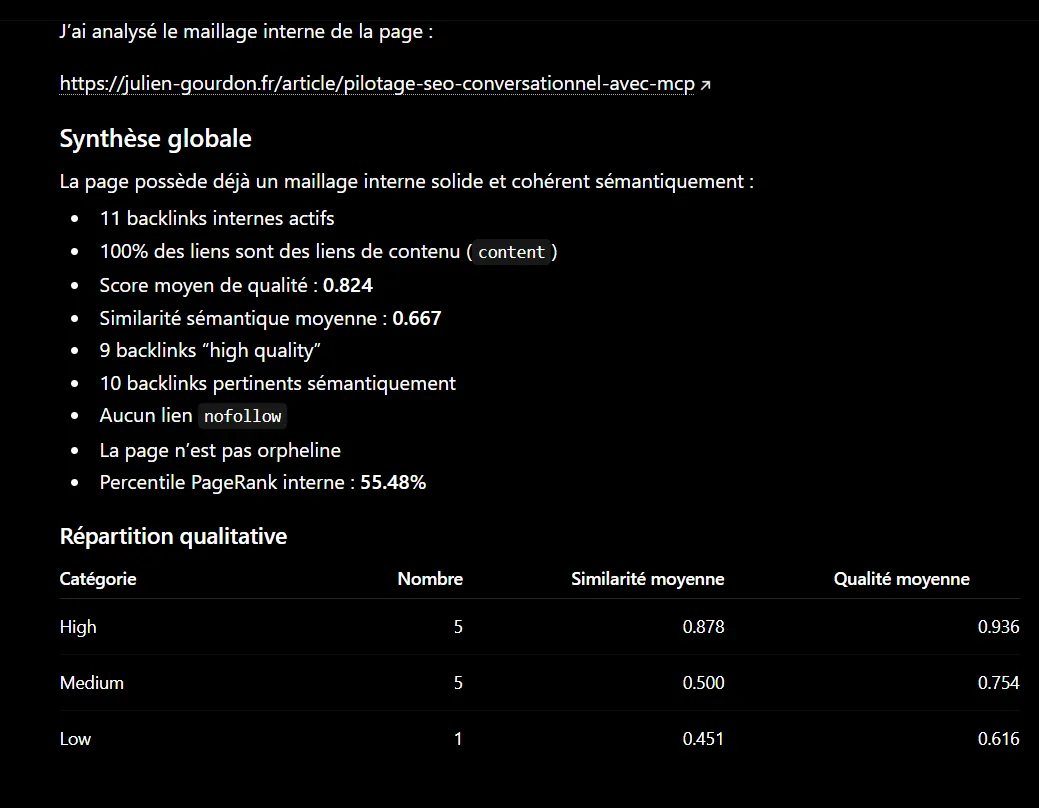
Une fois votre base de données Supabase connectée à votre interface d'assistance (comme ChatGPT ou un agent Codex), vous pouvez formuler des requêtes d'analyse stratégique complexes.
Voici trois scénarios de requêtes directes à soumettre à votre assistant connecté à la base :
Scénario 1 : Détecter les déficits de maillage interne
« Analyse la table
rag_pageset la tablerag_links. Identifie les 15 pages ayant le score de PageRank le plus faible. Pour chacune, parcours la tablerag_chunkset suggère trois paragraphes issus d'autres pages sémantiquement proches qui pourraient naturellement accueillir un lien pointant vers ces pages faibles. »
Scénario 2 : Traquer la sur-optimisation des ancres
« Regroupe les entrées de la table
rag_linkspartarget_url. Pour chaque URL cible, calcule la diversité de ses ancres. Signale-moi les pages qui reçoivent plus de 70 % de liens avec une ancre strictement identique. Propose des variations d'ancres plus naturelles en te basant sur le contexte sémantique des chunks d'origine correspondants. »
Scénario 3 : Analyse d'isolation thématique
« Identifie les pages dont la distance sémantique par rapport au centroïde du site est supérieure à la moyenne. Indique-moi si ces pages partagent des liens avec le reste du site ou si elles se comportent comme des silos isolés. »
Recommandation stratégique
La mise en œuvre de ce système marque la fin des analyses de maillage basées sur de simples correspondances de mots-clés. Attention cependant, la proximité sémantique calculée par un modèle vectoriel n'est pas une preuve absolue d'opportunité SEO : elle indique une cohérence de sujet.
Pour maximiser l'efficacité de vos décisions, je vous conseille de croiser les données de cette base sémantique avec vos données réelles de trafic et d'impressions issues de la Search Console. Un lien interne performant doit non seulement être sémantiquement logique, mais il doit également relier une page forte à fort trafic vers une page stratégique en phase de conversion. Utilisez ce RAG comme une boussole thématique, mais gardez toujours l'œil sur l'intention de recherche réelle de vos utilisateurs.

Commentaires
Aucun commentaire pour le moment. Soyez le premier à commenter !
Ajouter un commentaire