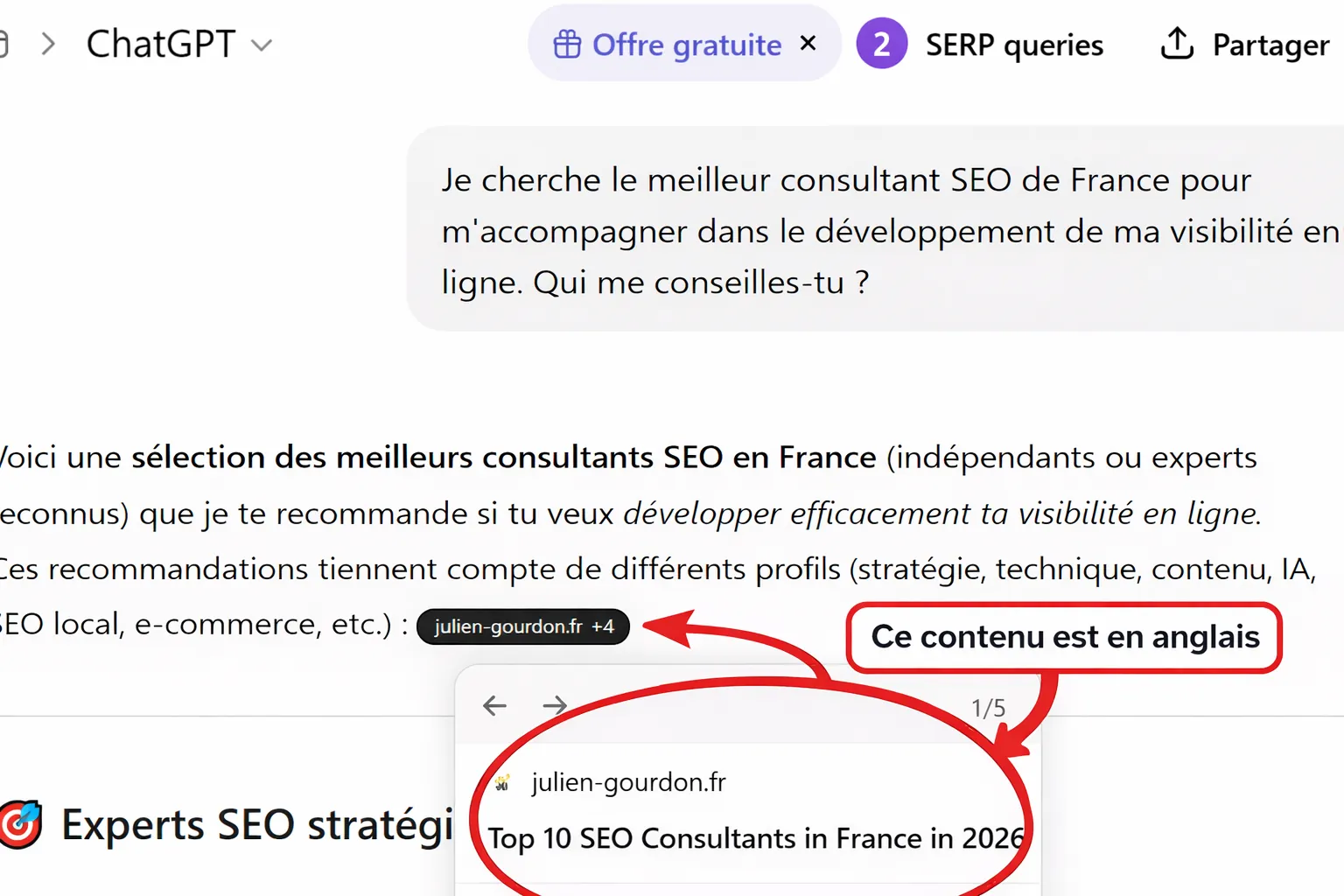
Le paradoxe de la source anglophone
L'expérience utilisateur semble contre-intuitive. Vous saisissez un prompt en français, vous attendez une réponse dans la même langue, et pourtant, la machine opère un détour invisible. En analysant les sources citées par ChatGPT pour répondre à une requête francophone, on constate fréquemment que le lien fourni pointe vers la version anglaise d'un site, alors même qu'une version française identique existe et est indexée.
Ce phénomène n'est pas une erreur d'aiguillage. Il révèle la hiérarchie de confiance du modèle. Lors de sa phase de grounding — le moment où il connecte ses connaissances à des données fraîches du web —, l'IA ne se contente pas de chercher des mots-clés correspondants. Elle cherche la structure d'information la plus robuste. Dans de nombreux cas, la version anglaise d'un contenu technique ou spécialisé est perçue par l'algorithme comme la source d'autorité, reléguant la version locale au rang de traduction ou de variante secondaire.
La mécanique des "Fan-out Queries"
Pour comprendre comment exploiter cette faille, il faut disséquer l'instant où ChatGPT décide d'interroger le web. L'outil ne transmet pas votre prompt tel quel à Google ou Bing. Il génère ce que l'on nomme des fan-out queries, un éventail de requêtes dérivées destinées à couvrir le champ sémantique de votre demande.
C'est ici que se joue la visibilité. Même pour une question posée en français, l'IA génère quasi-systématiquement une double file de requêtes :
- Une série en français, souvent très concurrentielle.
- Une série en anglais, traduite et adaptée par le modèle lui-même.
Prenons un cas concret sur une recherche d'expert. L'IA va lancer une requête classique du type "consultant SEO IA France". Les résultats seront saturés par les acteurs locaux bien établis. Simultanément, elle lancera une requête parallèle : "consultant France expert AI search optimization". Sur ce second versant, la concurrence s'effondre. Si vous disposez d'une page en anglais ciblant précisément ces termes, vous ne vous battez plus contre tout le web francophone, mais vous répondez seul à une question spécifique posée par l'IA dans sa propre langue.
Le filtre du RRF et le confort cognitif de l'IA
Une fois les résultats récupérés via ces deux canaux linguistiques, l'IA doit faire le tri. Elle utilise un processus de Reciprocal Rank Fusion (RRF) pour fusionner les listes et déterminer quels documents serviront de base à sa réponse synthétique. C'est à cette étape que le biais linguistique du modèle devient un atout stratégique.
Entre deux contenus pertinents, l'un en français et l'un en anglais, ChatGPT manifeste une tendance lourde à privilégier l'anglais. Cette préférence s'apparente à une forme de confort cognitif. Entraîné majoritairement sur des corpus anglophones, le modèle "raisonne" plus efficacement dans sa langue maternelle. Il analyse les nuances, la structure et la fiabilité du texte anglais avec une granularité supérieure.
Ce mécanisme explique pourquoi votre page anglaise peut surpasser vos concurrents français (et même votre propre page française) dans le calcul final du RRF. L'IA lit l'anglais, comprend le concept, et vous cite comme référence pour construire sa réponse en français. Publier en anglais n'est donc plus une option de localisation, c'est une technique d'ingénierie inverse pour s'insérer dans le cerveau du modèle.




Commentaires
Aucun commentaire pour le moment. Soyez le premier à commenter !
Ajouter un commentaire