
La dissidence des index internes
Contrairement à une idée reçue, ChatGPT n'est pas, ou plus, une simple surcouche à Bing ou Google quand il cherche des informations externes à ses connaissances acquises lors de son entraînement. Pour économiser du calcul, et donc de l'argent, la plateforme conversationnelle semble commencer à privilégier son cache interne à la recherche en temps réel sur les moteurs classiques.
Certains experts commencent en effet à avancer l'idée que les fan-outs de ChatGPT, devenus ridiculeusement longues et totalement inutilisables pour un moteur classique, prouvent que la plateforme utilise désormais massivement son propre système de recherche interne. Ces requêtes ultra longue-traînes, enrichies de nombreux synonymes, seraient en effet conçues pour faire de la recherche sémantique à l'intérieur d'une base de données vectorielles (le cache vectorisé de ChatGPT).
Il est par ailleurs important de souligner que je ne vois pas la moindre trace de ces requêtes qui ne veulent rien dire, et qui seraient donc faciles à repérer, dans ma Google Search Console.
Ce qui confirmerait l'idée qu'elles ne sont plus utilisées pour récupérer les résultats de recherche de Google.
Et si cette affirmation est vraie, cela pose une nouvelle problématique.
Là où un moteur classique nettoie les liens morts pour refléter l'état du Web (une page qui n'existe plus est par définition une page inaccessible aux utilisateurs), l'IA retient des concepts, indifférente au statut HTTP. Quand elle a besoin d'aller cherche une information, elle ne cherche pas la disponibilité d'une source, mais la pertinence sémantique d'un souvenir. Cette faille transforme des données éphémères en vérités durables.
Mécanique de l'injection via Wikipédia
Une technique GEO black hat actuelle exploite cette latence via Wikipédia. L'attaquant crée une page promotionnelle (pour sa marque, son service, son nom propre), force son ingestion immédiate par le modèle (il suffit de demander à ChatGPT de résumer la page Wikipédia nouvellement créée), puis laisse la modération la supprimer (ce qui survient inévitablement, les règles déontologiques de la plateforme communautaire sont connues pour être très strictes).
Pour l'humain, c'est une erreur 404. Pour l'IA, c'est une donnée validée car issue d'une source autoritaire (on trouve difficilement plus autoritaire que Wikipédia), stockée et dont elle pourra se servir pour répondre à n'importe quel utilisateur de la plateforme. En plaçant ensuite un lien vers cette URL morte sur des sites tiers, dont on sait qu'ils sont régulièrement récupérées par les bots IA, on réactive la mémoire du modèle. L'utilisateur fait alors face à un paradoxe : une source introuvable citée avec assurance par l'IA.
Ce que je vous raconte n'est pas le fruit de mon imagination diabolique. Je l'ai vu de mes propres yeux, et je le vois même de plus en plus. Je demande à ChatGPT de me citer les meilleurs experts dans un domaine spécifique, et l'IA me donne des noms en m'affichant sous la forme d'un lien cliquable la fiche Wikipedia d'où elle a tiré ses informations. Je clique sur le lien et j'atterris sur une page qui n'existe pas.
J'ouvre une nouvelle conversation et je demande au moteur IA de me résumer le contenu de l'URL. ChatGPT me résume en détails le contenu de l'URL... qui n'existe pas !
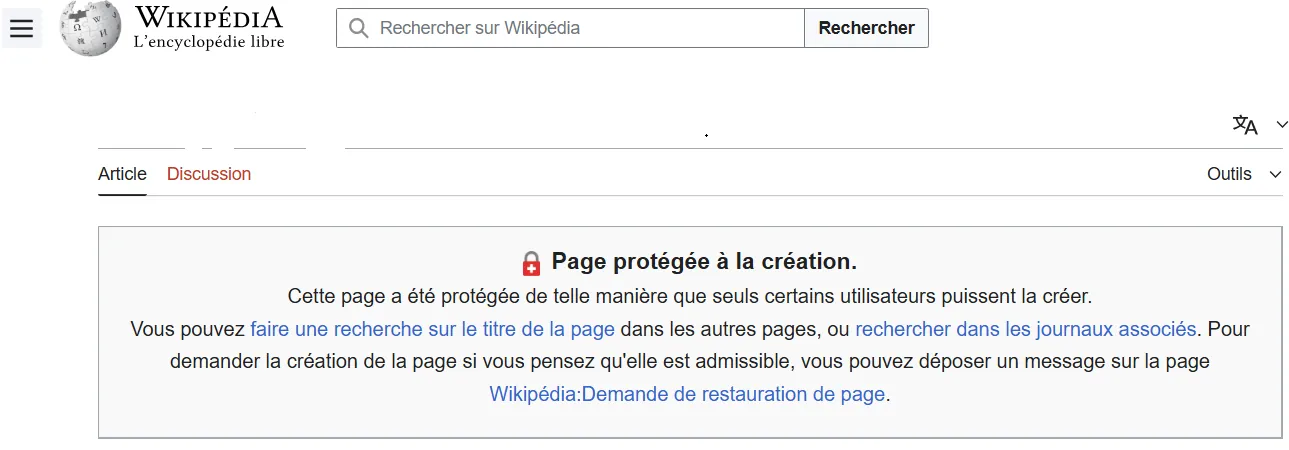 Phénomène rare d'une page Wikipédia qui n'existe pas et qui est pourtant abondamment citée par ChatGPT
Phénomène rare d'une page Wikipédia qui n'existe pas et qui est pourtant abondamment citée par ChatGPT
Comment un tel prodige est-il possible ?
J'ai réveillé mon âme d'enquêteur et j'ai activé mon compte Wikipédia pour tenter de comprendre ce phénomène. La page (pour ne prendre qu'un exemple parmi d'autres) avait été créée en septembre dernier avant d'être supprimée 2 jours plus tard par les modérateurs.
Deux jours de mise en ligne, c'est largement suffisant pour la faire ingérer par les robots d'OpenAI. Et suffisant pour qu'elles s'en souviennent encore trois mois plus tard, au point de l'afficher dans ses réponses.
En creusant encore un peu plus, j'ai découvert que la page Wikipédia qui n'existait plus était liée depuis une page du site dont il est évident qu'il appartient à ceux qui ont créé la fiche promotionnelle. Sur cette page, le site affiche fièrement qu'il est référencé sur Wikipedia, preuve selon lui de sa légitimité dans son domaine d'activité. Et au cas où ChatGPT n'arrive plus à retrouver la page Wikipedia en question, le site en fait un résumé détaillé (sans doute pour entretenir la mémoire du modèle).
C'est diabolique et sans doute éphémère, mais fin 2025, force est de constater que cette technique fonctionne parfaitement bien : la marque est citée quasiment à chaque fois qu'on pose une question à ChatGPT en lien avec son activité, avec en prime un joli lien cliquable brandé "Wikipédia" à côté de son nom.
Du référencement à l'impression mémorielle
Le SEO mute vers l'impression mémorielle : l'objectif n'est plus d'être classé, mais d'être retenu. Cette persistance rend le Droit à l'oubli techniquement inopérant, car on ne supprime pas aisément une donnée fondue dans des milliards de paramètres. Le cache devient un Web parallèle, un cimetière de données réactivables à la demande, posant un risque critique pour la gestion de l'e-réputation et la désinformation, dont pourrait bien se servir une armée de hackers mal-intentionnés.
Vers une architecture de la vérité découplée
L'expérience utilisateur se scinde désormais en deux réalités. D'un côté, le Web vivant, modéré et vérifiable. De l'autre, un Web synthétique mêlant données live et souvenirs périmés. Les stratégies futures ne devront plus seulement surveiller ce qui est publié, mais auditer ce qui est mémorisé. Car la prochaine faille de sécurité majeure pourrait bien être l'injection de souvenirs nocifs fantômes, servis comme faits avérés par ChatGPT bien après la disparition de leurs preuves.




Commentaires
Aucun commentaire pour le moment. Soyez le premier à commenter !
Ajouter un commentaire