
Si comme moi, vous êtes un passionné du référencement naturel, vous avez certainement déjà entendu parler du DUST. Pour ceux qui sont novices en revanche, il y a peu de chance que vous sachiez à quoi cela fait référence. Cet acronyme signifie "Duplicate URL, Same Text" et désigne un phénomène souvent méconnu mais qui peut impacter le SEO d'un site web. Dans cet article, je vous explique en détails ce qu'est le DUST, pourquoi il constitue un problème pour les moteurs de recherche, et comment éviter ses pièges.
Définition de DUST en SEO
DUST désigne une situation où plusieurs pages identitiques d'un site web sont accessibles via des URL différentes. Par exemple, il arrive que pour un site, les URL suivantes mènent toutes à la page d'accueil de monsite.com :
- https://www.monsite.com
- https://monsite.com
- https://www.monsite.com/index.html
- https://monsite.com/index.html
Ce problème peut également se rencontrer lorsqu'un site est migré vers un nouveau domaine ou un nouveau système de gestion de contenu (CMS), et que des redirections mal configurées entraînent une duplication de certaines URL. Ou encore, lorsque plusieurs versions d'une page sont accessibles via différentes URLs (en raison des paramètres de session ou des paramètres de recherche), cela peut également entraîner de la duplication de contenu
Si vous avez ne saisissez pas l'importance de ce problème, je vais vous donner une analogie : imaginez que chaque page de votre site est une maison, et chaque URL est une adresse. Le DUST serait comme si vous aviez plusieurs adresses menant à la même maison. Imaginez la confusion pour les visiteurs 🙄.
Conséquences du DUST sur le référencement
Mais là où ça devient un vrai problème, c'est lorsque ce ne sont pas seulement les visiteurs d'un site internet qui sont confus, mais également les robots des moteurs de recherche.
Les bots des moteurs de recherche ont en effet pour mission (parmi d'autres) :
- d'identifier quelles URLs inclure ou exclure de l'index du moteur de recherche ;
- d'attribuer correctement la valeur des liens (confiance, autorité, etc.) pour chaque URL ;
- de classer les URL pour les résultats de recherche.
Si les robots identifient plusieurs URL avec un contenu strictement identique (problèmatique de duplicate content), ils sont obligés de faire un choix. Et sans indication de votre part, ce choix pourrait ne pas être le vôtre !
Comment prévenir et corriger ces problèmes ?
Maintenant que nous avons identifié les possibles répercussions du "Duplicate URL, Same Text" sur le référencement, voyons comment détecter, corriger et prévenir ces problèmes.
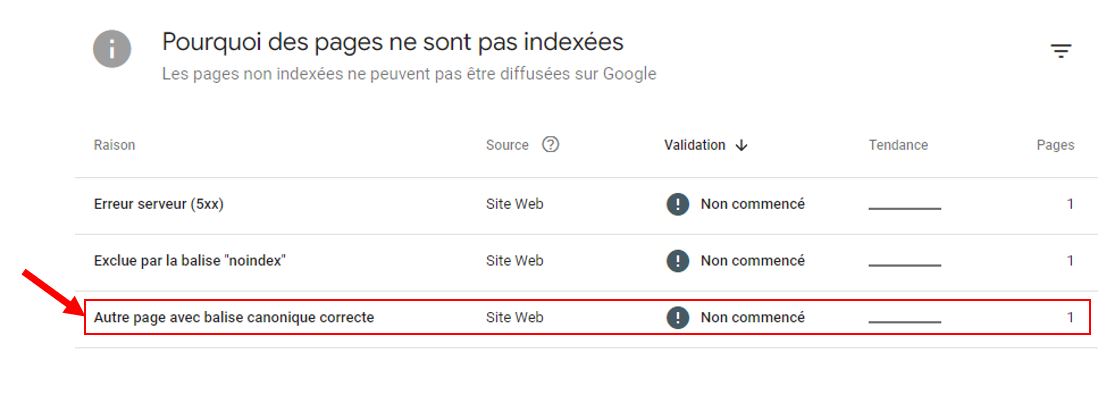 La Search Console permet d'identifier les pages en double pour lesquelles Google a choisi une autre URL comme page de référence.
La Search Console permet d'identifier les pages en double pour lesquelles Google a choisi une autre URL comme page de référence.
- Détecter les URL en double : utilisez un crawler de type Screaming Frog pour analyser votre site et identifier les URL en double
- Choisir une version canonique : parmi toutes les URL en double sur votre site, vous devez en choisir une qui fait référence, c'est à dire la version canonique ou originale.
- Corriger les liens internes de votre site : assurez-vous que les pages de votre site font un lien vers la version canonique choisie, et non pas sa ou ses versions en double. Là encore, vous pouvez utiliser l'outil Screaming Frog pour identifier les liens qui pointent vers les pages en double de votre site.
- Utiliser la balise 'link rel="canonical"' : Cette balise doit être implémentée dans le 'head' de votre page originale. Elle permet de préciser à Google quelle URL est la version originale du contenu, même si des URL en double existent.
- Mettre en place des redirections 301 : redirigez les URL en double vers l'URL canonique choisie. Si vous ne le faîtes pas pour telle ou telle raison, insérez obligatoirement une balise canonique sur vos pages en double qui pointe vers votre contenu original. Attention cependant. La balise canonique n'est qu'une indication qu'on donne aux robots des moteurs de recherche. Ils ne sont pas obligés de la suivre. Pour vérifier si Google a choisi une autre page comme contenu principal que celle sur laquelle vous avez posé une balise canonical auto-référente, rendez-vous dans la Google Search Console, dans la partie "Indexation", et cliquez sur l'onglet "Pages". S'il est affiché, cliquez sur le texte "Autre page avec balise canonique correcte" et vous aurez accès à toutes vos pages que Google a choisi de ne pas indexer parce qu'il considère qu'une autre page est plus pertinente que celle sur laquelle vous avez posez une canonique auto-référente.
- Mettre en oeuvre une stratégie unifiée : assez-vous que toutes les pages de votre site utilisent le même format d'URL, et informez tous les contributeurs (rédacteurs, développeurs, etc.) des bonnes pratiques à suivre.
Enfin, je vous conseille de crawler régulièrement votre site afin de détecter d'éventuels problèmes de DUST.
Questions fréquentes à propos du DUST en SEO
Les sites web multilingues sont-ils plus susceptibles de rencontrer ces problèmes ?
Les sites web multilingues peuvent effectivement être plus susceptibles de rencontrer des problèmes de "Duplicate URL, Same Text", car ils ont souvent plusieurs versions d'une même page pour différentes langues. Pour résoudre ce problème, vous pouvez utiliser la balise hreflang, qui indique aux moteurs de recherche la langue et la région géographique d'une page.
Quel rôle les sitemaps XML jouent-ils dans la prévention et la résolution des problèmes de DUST ?
Les sitemaps XML peuvent effectivement jouer un rôle important dans la prévention et la résolution des problèmes de DUST dans la mesure où Google recommande de ne répertorier dans ces fichiers que les URL canoniques de votre site. C'est donc une indication supplémentaire pour Google que les URL qui se trouvent dans votre fichier sitemap XML sont celles que vous voulez voir indexées, au détriment des éventuelles URL en doublon sur votre site.
Les CMS de type WordPress sont-ils plus enclins à provoquer des problèmes de DUST ? Si oui, comment les éviter ?
Certains CMS peuvent effectivement créer des problèmes de DUST, notamment en générant automatiquement plusieurs URL pour un même contenu. Pour éviter cela, vous pouvez utiliser des plugins SEO qui vous permettent de contrôler les URL de vos pages.

Commentaires
Aucun commentaire pour le moment. Soyez le premier à commenter !
Ajouter un commentaire