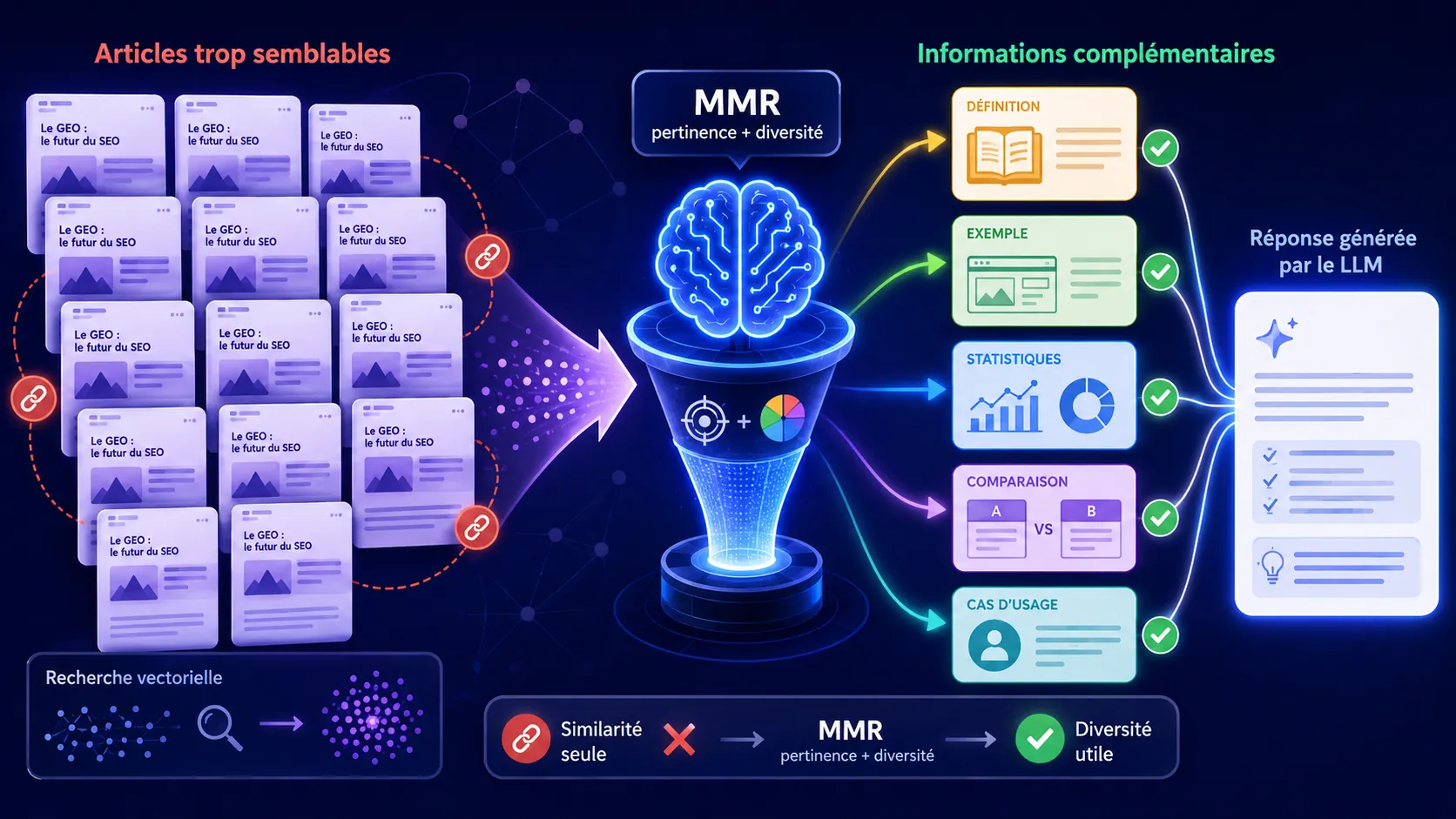
Quand les résultats les plus proches finissent par se ressembler
Une recherche fondée sur des word embeddings transforme une requête et des contenus en vecteurs, puis mesure leur proximité dans un espace sémantique. Cette mécanique permet de retrouver des documents qui parlent d'un même sujet, même lorsque les mots employés diffèrent.
Le problème apparaît lorsque plusieurs résultats couvrent exactement le même angle. Pour une requête sur les effets du télétravail, les cinq premiers passages peuvent tous expliquer qu'il réduit les temps de transport. Ils sont pertinents, mais les suivants ajoutent peu de matière nouvelle. C'est un peu comme remplir une bibliothèque avec plusieurs éditions du même livre : les rayonnages sont pleins, la connaissance beaucoup moins.
Ce phénomène est courant avec le chunking sémantique. Lorsque les fenêtres se chevauchent, deux chunks voisins peuvent partager une grande partie de leur contenu. L'overlap préserve le contexte, mais produit aussi des quasi-doublons. MMR peut limiter cet effet sans réparer un découpage mal conçu.
La distinction est importante. La proximité sémantique mesure à quel point un contenu correspond à la requête. La valeur marginale mesure plutôt ce que ce contenu apporte une fois les premiers résultats déjà choisis. Les deux critères se complètent, mais ils ne racontent pas la même histoire.
Comment fonctionne la sélection MMR
L'algorithme procède de manière progressive. Il commence généralement par retenir le résultat le plus pertinent pour la requête. Ensuite, pour chaque candidat restant, il évalue à la fois sa proximité avec la requête et sa ressemblance avec les éléments déjà sélectionnés.
Sa forme simplifiée peut s'écrire ainsi :
score MMR = λ × similarité avec la requête − (1 − λ) × similarité maximale avec les résultats déjà retenus
Le premier terme récompense la pertinence. Le second applique une pénalité de redondance. Un document très proche de la requête peut donc perdre des points s'il ressemble fortement à un passage déjà présent dans la sélection. À l'inverse, un candidat légèrement moins proche peut passer devant lorsqu'il couvre un aspect complémentaire.
Prenons une recherche sur « optimiser un pipeline RAG ». Le premier résultat explique la vectorisation. Trois autres décrivent presque la même étape, tandis que deux candidats traitent du filtrage des métadonnées et de l'évaluation. Un classement par similarité peut privilégier les quatre textes sur la vectorisation. MMR tendra plutôt à conserver le meilleur, puis à faire entrer les deux angles complémentaires.
L'algorithme recherche ainsi une nouveauté pertinente, pas une diversité abstraite. Un contenu très différent mais hors sujet n'a aucune raison d'être sélectionné pour la seule variété.
Le paramètre λ règle la largeur du champ
Le paramètre λ, compris entre 0 et 1, détermine le poids accordé à la pertinence par rapport à la diversité. Avec λ = 1, la pénalité de redondance disparaît : le classement revient à favoriser la pertinence pure. Avec λ = 0, la diversité domine, au risque de retenir des éléments trop éloignés de l'intention initiale.
Les valeurs intermédiaires sont les plus intéressantes, mais aucune ne convient partout. Une requête précise, portant sur une référence juridique ou un produit identifié, supporte mal une diversification excessive. Une recherche exploratoire sur l'IA dans la santé gagne au contraire à faire émerger plusieurs angles : diagnostic, organisation hospitalière, recherche, éthique ou protection des données.
Le réglage dépend aussi du nombre de candidats examinés. MMR intervient souvent après une récupération top-k : le système remonte 30 passages, puis en sélectionne 5 ou 8. Diversifier un bassin médiocre ne donnera jamais une excellente sélection. L'algorithme agit comme un commissaire d'exposition : il agence les œuvres disponibles, il ne les crée pas.
Cette étape a un coût : chaque candidat doit être comparé aux éléments déjà retenus. En production, MMR est donc généralement limité à une fenêtre de reranking plutôt qu'appliqué à l'ensemble de l'index.
Dans un système RAG, chaque chunk doit mériter sa place
Dans un système RAG, la récupération ne constitue qu'une étape. Les passages retenus sont ensuite injectés dans le contexte du modèle afin de l'aider à produire une réponse. Or cette fenêtre n'est pas infinie, et même lorsqu'elle est large, l'accumulation de contenus répétitifs peut diluer les informations importantes.
Cinq chunks disant presque la même chose créent une illusion de richesse documentaire et laissent moins de place aux exceptions, aux chiffres ou aux conditions d'application. MMR cherche à transformer cette pile de résultats en petit dossier cohérent.
Avec des contenus longs découpés en segments superposés, le système peut récupérer plusieurs fragments issus du même paragraphe. MMR peut favoriser le passage central, puis ouvrir la sélection à d'autres sections ou documents. Des règles par URL ou catégorie peuvent aussi empêcher une seule source de monopoliser le contexte.
MMR ne dispense toutefois pas d'un bon travail en amont. Des chunks mal délimités, privés de leur sujet ou remplis de bruit sémantique resteront difficiles à exploiter. La diversification améliore une sélection déjà convenable ; elle ne remplace ni la qualité des embeddings, ni la structuration documentaire, ni l'évaluation du retriever.
Reranking, RRF et apprentissage du classement
MMR intervient généralement comme une couche de reranking. Une première recherche, vectorielle, lexicale ou hybride, produit une liste de candidats. L'algorithme réordonne ensuite cette liste en intégrant la redondance entre les résultats.
Il faut le distinguer du Reciprocal Rank Fusion. RRF combine plusieurs classements, par exemple un classement BM25 et un classement vectoriel, à partir de la position des documents dans chaque liste. MMR répond à une autre question : parmi les candidats disponibles, lesquels formeront l'ensemble final le moins répétitif tout en restant pertinent ?
Les deux approches peuvent d'ailleurs se suivre. Un moteur hybride peut fusionner ses résultats grâce à RRF, appliquer un modèle de learning to rank pour intégrer des signaux supplémentaires, puis utiliser MMR sur les premiers candidats afin de diversifier la sélection finale. Le passage ranking peut lui aussi fournir les unités fines que MMR devra départager.
Cette succession n'est pas obligatoire, mais elle montre que la pertinence moderne se construit souvent en plusieurs étages : récupération, fusion, estimation de qualité, diversification, puis génération.
Ce que cette logique change pour le GEO
Il serait imprudent d'affirmer que tous les moteurs génératifs utilisent MMR, ou qu'ils l'emploient exactement sous sa forme académique. Leurs architectures restent largement opaques et peuvent mobiliser d'autres méthodes de diversification, de regroupement ou de déduplication. MMR offre néanmoins une grille de lecture utile pour comprendre un principe général : la meilleure source n'est pas toujours la plus semblable, mais parfois celle qui complète le mieux les autres.
Dans une stratégie de Generative Engine Optimization, répéter une définition consensuelle avec des synonymes peut renforcer la proximité avec une requête. Cela ne garantit pas qu'un passage sera retenu si plusieurs sources apportent déjà la même information. Sa valeur marginale reste faible.
Un contenu devient plus utile au corpus lorsqu'il apporte une distinction nette : une donnée originale, une méthode détaillée, un exemple de terrain, une limite rarement évoquée, un tableau comparatif ou une relation entre deux concepts souvent séparés. La singularité gratuite n'aide pas. L'originalité doit rester attachée à l'intention de recherche.
C'est probablement l'enseignement le plus fécond de MMR pour le GEO. Une page ne devrait pas seulement chercher à ressembler au meilleur résultat existant. Elle devrait aussi se demander quelle pièce manque encore au puzzle documentaire. Cette pièce peut être modeste, mais suffisamment précise pour rendre l'ensemble plus complet.
Écrire des contenus plus favorables à une sélection diversifiée
Un contenu susceptible d'être retenu dans ce type de sélection doit d'abord couvrir correctement le besoin principal. La différenciation ne compense jamais un hors-sujet. Il faut ensuite formuler des définitions autonomes et ajouter des éléments qui résistent à la paraphrase générique : chiffres sourcés, observations personnelles, cas précis, critères de décision, contre-exemples ou limites. Chaque section doit conserver un sujet identifiable afin que son sens survive au découpage en chunks.
Les exemples concrets jouent ici un rôle décisif. Dire que MMR réduit la redondance reste exact, mais assez commun. Montrer comment un overlap de 20 mots entre des chunks peut faire remonter trois fragments voisins, puis expliquer comment la pénalité de similarité modifie la sélection, produit un passage plus démonstratif et plus facile à citer.
Il faut aussi éviter de multiplier artificiellement les variantes d'une même idée. Un article peut être long et pourtant pauvre en information marginale. À l'inverse, un passage bref, dense et bien délimité peut devenir la brique qui manquait à une réponse générative.
MMR rappelle finalement une règle éditoriale ancienne, remise au goût du jour par les architectures vectorielles : occuper le terrain ne suffit pas. Il faut apporter une raison de rester dans la sélection. Dans un web où les contenus s'imitent parfois comme des miroirs placés face à face, la différence utile devient une forme de pertinence à part entière.
Commentaires
Aucun commentaire pour le moment. Soyez le premier à commenter !
Ajouter un commentaire